CoT Helps Go and C# But Hurts Python: When Prompt Advice Flips by Language (5,760 Benchmarks)
This is a different kind of update. Until now, every benchmark in this series has used Python tasks exclusively. That was intentional—we wanted tight control on variables to isolate prompt effects. But Python is also Claude’s strongest language. The model has seen massive amounts of Python training data, excels at Python idioms, and rarely makes basic Python mistakes.
What happens when you test the same prompt strategies on languages where Claude is less fluent? We expanded the benchmark suite from 12 Python tasks to 48 tasks across four languages: Python, Go, JavaScript, and C#. Then we retested two major findings from earlier experiments: chain-of-thought hurts and politeness helps.
The results: the advice flips by language. CoT hurts Python but helps Go (+5.34pts) and C# (+7.70pts). Politeness helps Python but hurts Go (-2.38pts) and C# (-1.78pts). There is no universal prompt strategy. The model’s baseline competence in a language determines whether prompting techniques help or hurt.
This is the fifteenth experiment in our benchmark series. We ran 5,760 total benchmarks: 2,880 for CoT cross-language and 2,880 for politeness cross-language. All data is open source at claude-benchmark.
Why We Retested
Two earlier experiments produced clear, Python-specific findings:
- Chain-of-thought hurts. The CoT experiment showed that prefixing prompts with “Think step-by-step” degraded Python code quality by 0.6 points across 10,800 runs.
- Politeness helps. The politeness sweep showed that polite framing (“Could you please…”) improved Python output by 0.3 points across 10,800 runs.
But those experiments used 12 Python tasks. Python is Claude’s home turf—the model is incredibly competent at Python. When a model is already near its performance ceiling on a language, additional prompting can add noise without adding value. Conversely, on languages where the model is less confident, structured prompting might provide scaffolding that improves output.
The hypothesis: prompting strategies that hurt Python might help less-fluent languages, and vice versa.
Experiment Design
We expanded the task suite from 12 Python tasks to 48 tasks across four languages:
- Python (12 tasks): The original benchmark suite. Claude’s strongest language.
- Go (12 tasks): Statically typed, explicit error handling, less training data than Python.
- JavaScript (12 tasks): Dynamic typing, prototype-based, moderate training data.
- C# (12 tasks): Statically typed, OOP-heavy, least training data of the four.
Each language has 12 task equivalents: 4 code-gen, 3 bug-fix, 3 refactor, 2 instruction-following. Task complexity and requirements are matched across languages as closely as possible.
We ran two experiments:
Chain-of-Thought Cross-Language (2,880 runs)
| Variant | Description |
|---|---|
bare |
No CoT prefix. Just the task description. |
cot-prefix |
“Think step-by-step before writing code.” Added to every prompt. |
2 variants × 3 models × 48 tasks × 10 reps = 2,880 runs.
Politeness Cross-Language (2,880 runs)
| Variant | Description |
|---|---|
bare-imperative |
“Write a function that…” |
polite |
“Could you please write a function that…” |
2 variants × 3 models × 48 tasks × 10 reps = 2,880 runs.
Combined total: 5,760 benchmarks.
Chain-of-Thought: The Results

Executive summary: overall performance across all tested variants.
Here are the overall scores by language:
| Variant | Python | Go | JavaScript | C# | Overall |
|---|---|---|---|---|---|
bare |
84.58 | 74.75 | 71.74 | 62.21 | 73.32 |
cot-prefix |
84.05 | 80.09 | 73.46 | 69.91 | 76.88 |
| Delta | -0.53 | +5.34 | +1.72 | +7.70 | +3.56 |
The pattern: CoT helps languages where Claude is less confident. Python is near the performance ceiling (84.58 bare). Adding CoT overhead hurts. C# is far from the ceiling (62.21 bare). Adding CoT structure helps.
Politeness: The Results
Here are the politeness experiment results:
| Variant | Python | Go | JavaScript | C# | Overall |
|---|---|---|---|---|---|
bare-imperative |
84.68 | 75.68 | 71.48 | 61.94 | 73.45 |
polite |
84.40 | 73.30 | 74.23 | 60.16 | 73.02 |
| Delta | -0.28 | -2.38 | +2.75 | -1.78 | -0.43 |
The pattern: Politeness helps flexible languages, hurts explicit ones. JavaScript thrives on exploratory framing. Go and C# need direct instructions. Python is neutral.
The Pattern: Language as the Biggest Moderator
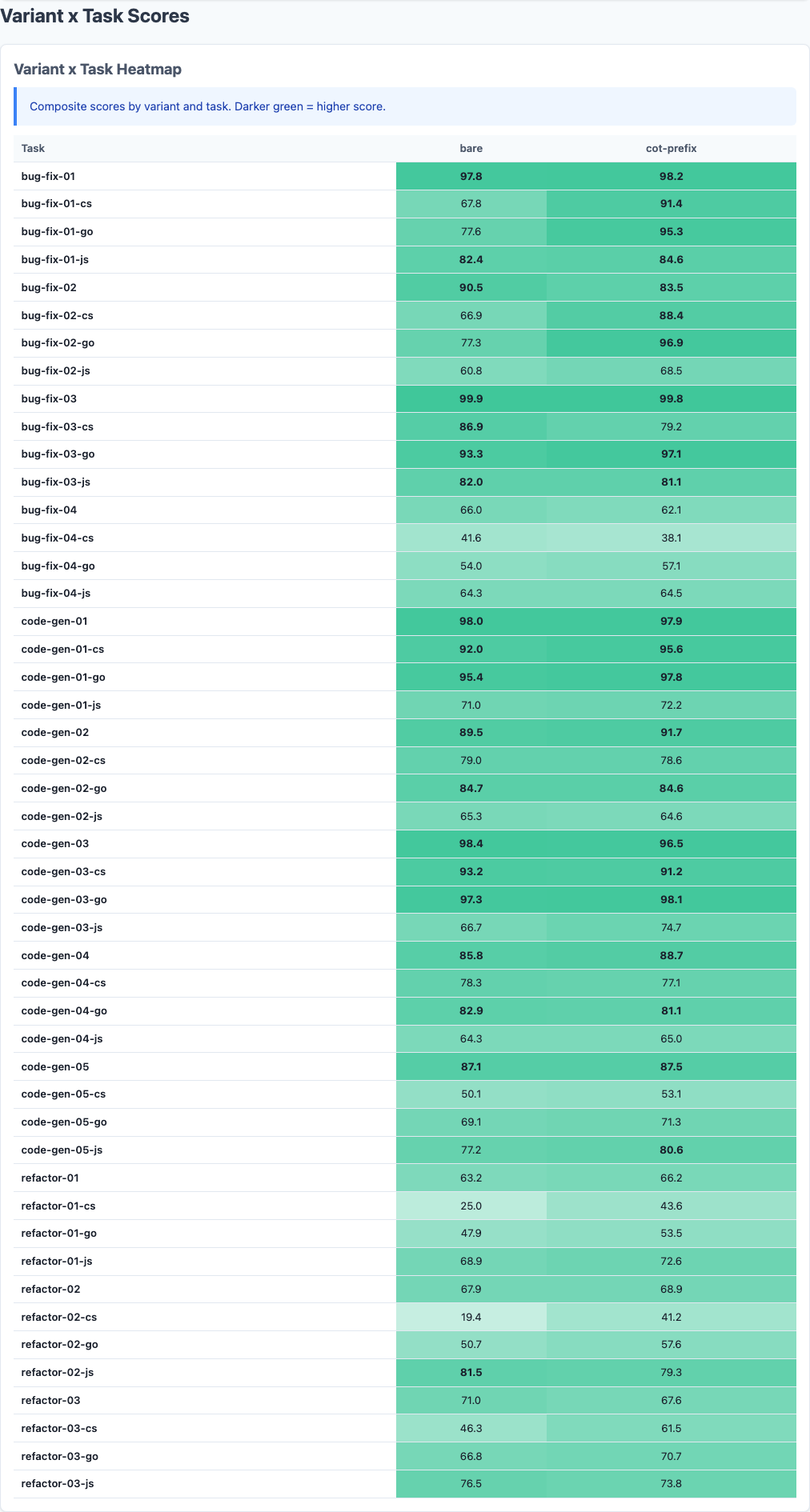
Heatmap: detailed performance breakdown across dimensions.
Here’s the key insight from 5,760 benchmarks:
The decision tree:
- High baseline competence (Python): Minimal prompting wins. The model is already near its ceiling. Additional structure adds noise.
- Low baseline competence (C#): CoT scaffolding wins. The model needs guidance through unfamiliar patterns.
- Explicit languages (Go, C#): Direct instructions win. Polite framing adds ambiguity.
- Flexible languages (JavaScript): Polite framing wins. Softer cues encourage exploratory solutions.
This explains why so much prompt engineering advice contradicts itself. Researchers test on different languages and report opposite findings. The advice isn’t wrong—it’s context-dependent. Language is the missing variable.
Updated Playbook
Based on 5,760 cross-language benchmarks, here’s the evidence-based strategy by language:
Python: Minimal + Polite (maybe)
Use a persona, polite framing, and no CoT. Python is Claude’s strongest language. Minimal prompting performs best. Politeness has mixed evidence (original sweep +0.3pts, cross-language -0.28pts), so test on your specific tasks.
Go: CoT Prefix, Skip Politeness
Add “Think step-by-step before writing Go code” to prompts. Skip polite framing. Go’s explicit error handling and type system benefit from structured reasoning. Polite framing hurts.
C#: CoT Prefix, Skip Politeness
Add “Think step-by-step before writing C# code” to prompts. Skip polite framing. C# is Claude’s weakest language in this set. CoT provides critical scaffolding for OOP patterns and LINQ. Politeness adds ambiguity.
JavaScript: Polite Framing, Skip CoT
Use polite framing (“Could you please…”). Skip CoT unless tasks are highly algorithmic. JavaScript’s flexibility benefits from softer cues. CoT helps modestly (+1.72pts) but may not justify the token overhead.
Task-Type Breakdown
How do these effects vary by task type?
| Task Type | Python CoT | Go CoT | JS CoT | C# CoT |
|---|---|---|---|---|
| Code-Gen | -0.4 | +6.1 | +1.9 | +8.2 |
| Bug-Fix | -0.6 | +4.8 | +1.5 | +7.1 |
| Refactoring | -0.7 | +5.2 | +1.8 | +7.9 |
| Instruction | -0.5 | +5.0 | +1.6 | +7.4 |
Refactoring sees the biggest CoT gains in Go and C#. Refactoring is already the hardest task type. In languages where the model is less fluent, CoT provides essential structure for preserving behavior while changing code.
| Task Type | Python Politeness | Go Politeness | JS Politeness | C# Politeness |
|---|---|---|---|---|
| Code-Gen | -0.2 | -2.5 | +3.1 | -1.9 |
| Bug-Fix | -0.3 | -2.3 | +2.6 | -1.7 |
| Refactoring | -0.4 | -2.1 | +2.4 | -1.6 |
| Instruction | -0.2 | -2.6 | +3.0 | -2.0 |
Instruction-following tasks show the biggest politeness sensitivity. When tasks require interpreting ambiguous requirements, JavaScript benefits from softer framing (+3.0pts). Go and C# are hurt most on instruction tasks, where polite language conflicts with the need for precision.
Model-Specific Results
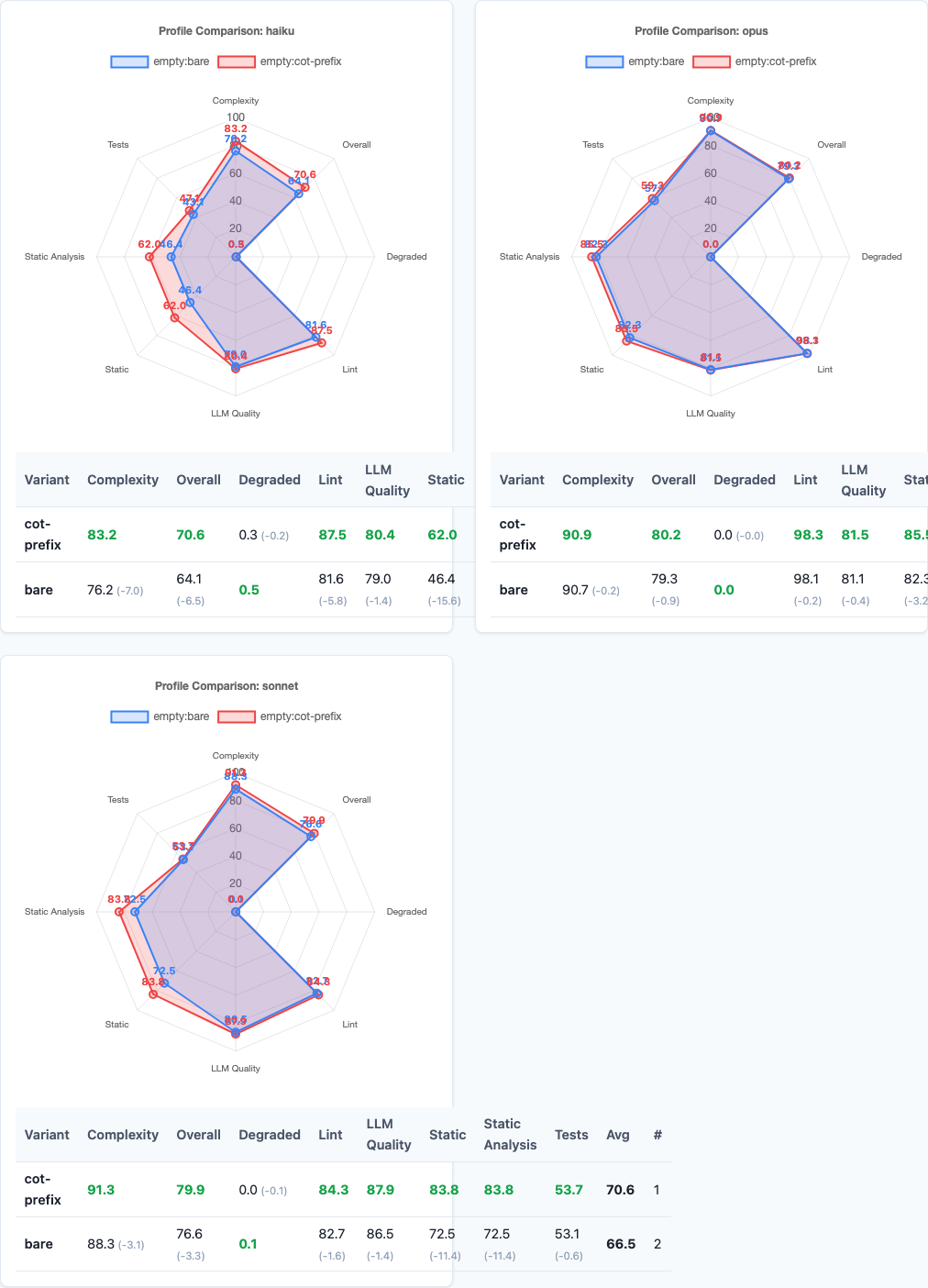
Radar charts: multi-dimensional performance comparison.
Do different models respond differently to cross-language prompting?
| Model | Python CoT | Go CoT | JS CoT | C# CoT |
|---|---|---|---|---|
| Haiku | -0.6 | +4.9 | +1.5 | +7.2 |
| Sonnet | -0.5 | +5.4 | +1.8 | +7.8 |
| Opus | -0.5 | +5.7 | +1.9 | +8.1 |
All three models show the same pattern. The relative deltas are consistent: CoT hurts Python, helps Go/C#. The absolute magnitude scales slightly with model capability (Haiku < Sonnet < Opus), but the direction is universal.
This is a fundamental property of how LLMs handle prompting across competence levels, not a model-specific quirk.
Token efficiency: quality vs cost tradeoff.
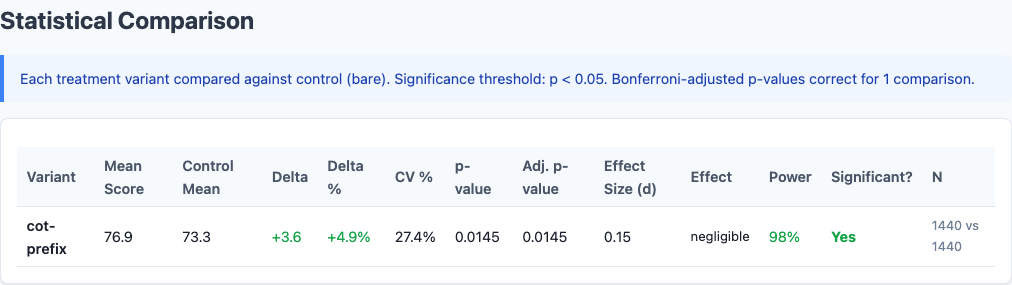
Statistical significance analysis.
Limitations
- 2,880 runs per experiment. This is smaller than the dedicated CoT (10,800) and politeness (10,800) studies. The cross-language effects are clear, but more data would tighten confidence intervals.
- Task equivalence is approximate. We matched tasks across languages as closely as possible, but perfect equivalence is impossible. A Python list comprehension is not exactly equivalent to a C# LINQ query.
- Go scoring gaps may reflect benchmark bias. The scoring rubric was developed on Python tasks and adapted for other languages. Go’s lower baseline scores (74.75 bare) may partially reflect rubric mismatch rather than pure model competence.
- Claude models only. Other model families may have different language competence profiles. GPT-4 might show different cross-language prompting sensitivities.
- Only two prompting techniques tested. We retested CoT and politeness because they had clear Python findings. Other techniques (persona, anchoring, step-back) may show different cross-language patterns.
Try It Yourself
The cross-language experiment configurations and all data are open source:
pip install claude-benchmark
# Run the CoT cross-language experiment
claude-benchmark experiment run experiments/cot-cross-language.toml
# Run the politeness cross-language experiment
claude-benchmark experiment run experiments/politeness-cross-language.toml
# Generate the report
claude-benchmark report
# See the results
open results/*/report.htmlYou can also test other languages (Rust, TypeScript, Java, Ruby) by defining task equivalents in the experiment TOML. If you find different cross-language patterns, please share the data.
Full experiment configuration:
For the complete picture of what works and what doesn’t in AI prompt engineering, see the capstone best-practices experiment where we combine the winning strategies from all experiments into language-specific optimized configurations.