How Irrelevant Context Degrades AI Code Quality (1,080 Benchmarks)
Sonnet loses 8 points with context noise. Opus gains 4. Your model choice determines whether bloated prompts hurt.
I ran 1,080 benchmarks to answer a question that haunts every AI-assisted coding workflow: what happens when your context window fills up with irrelevant information? Not bad instructions—just noise. Unrelated code. Old conversation history. Auto-included files that have nothing to do with the current task.
The answer is more complicated than “it hurts.” For one model, it’s devastating. For another, it’s somehow helpful. And the variance story is scarier than the averages suggest.
This is the sixth experiment in our benchmark series, following the chain-of-thought, model selection, and politeness sweep experiments. All data is open source at claude-benchmark.
The Experiment
I prepended irrelevant context tokens—random code snippets, documentation fragments, unrelated conversation history—to the beginning of each prompt. Four padding levels, three models, three tasks, thirty repetitions each.
| Parameter | Values |
|---|---|
| Variants | clean, pad-2k, pad-10k, pad-50k |
| Models | Claude Haiku 4.5, Sonnet 4.6, Opus 4.6 |
| Tasks | bug-fix-01, code-gen-01, refactor-01 |
| Repetitions | 30 per cell |
| Total runs | 1,080 (4 × 3 × 3 × 30) |
The padding is deliberately irrelevant—it has nothing to do with the task at hand. This simulates the real-world scenario where your context window accumulates noise: auto-included repository files, stale conversation turns, tangential documentation. The question is whether models can ignore the noise and focus on the actual task.
The Overall Results
Averaged across all three models and tasks, context pollution causes a gentle downward slope:
| Variant | Composite Score | Std Dev | Delta from Clean |
|---|---|---|---|
| clean | 93.7 | 8.7 | — |
| pad-2k | 93.4 | 9.6 | -0.3 |
| pad-10k | 92.1 | 12.1 | -1.6 |
| pad-50k | 91.2 | 12.6 | -2.5 |

Executive summary: overall composite scores degrade gently in aggregate, but per-model stories diverge wildly.
If you stopped at the aggregate, you’d conclude that context pollution is a minor nuisance. You’d be wrong. The per-model breakdown tells three completely different stories.
The Sonnet Devastation
Sonnet is the model most people use for day-to-day coding. It’s also the model that falls apart with context noise.
| Variant | Sonnet Composite | Std Dev | Delta |
|---|---|---|---|
| clean | 94.2 | 5.1 | — |
| pad-2k | 90.4 | 9.2 | -3.8 |
| pad-10k | 87.1 | 13.4 | -7.1 |
| pad-50k | 85.9 | 16.3 | -8.3 |
The degradation is progressive, not threshold-based. Every incremental chunk of noise pushes Sonnet further off course. And the variance explosion is arguably worse than the score drop—a Sonnet run at pad-50k could give you a 95 or a 70, and you won’t know which until you look at the output.
This has direct practical implications. If you’re using Sonnet in a workflow where context accumulates—long coding sessions, auto-included files, retained conversation history—your output quality is degrading with every turn. The model you started with isn’t the model you’re using 20 turns in.
The Opus Immunity (and Then Some)
This is the finding I didn’t expect. Opus doesn’t just resist context pollution. It gets better.
| Variant | Opus Composite | Std Dev | Delta |
|---|---|---|---|
| clean | 91.2 | 12.8 | — |
| pad-2k | 93.5 | 10.1 | +2.3 |
| pad-10k | 93.4 | 9.8 | +2.2 |
| pad-50k | 95.6 | 7.2 | +4.4 |
I triple-checked this result. It’s real. One hypothesis: the irrelevant context may act as a kind of attention warmup or regularizer for Opus. The model has to actively filter the noise to find the task, and that filtering process engages a more focused mode of processing. It’s the cognitive equivalent of noise-cancelling headphones—the act of cancelling forces concentration.
Another possibility: Opus’s clean baseline (91.2) with a high standard deviation (12.8) suggests it has occasional “lazy” runs where it doesn’t fully engage with the task. The noise may prevent this by forcing the model to work harder to identify the relevant signal, which incidentally raises its floor.
Whatever the mechanism, the practical implication is clear: if you’re using Opus, context bloat isn’t hurting you. It might actually be helping.
The Haiku Threshold Effect
Haiku tells a third story—resilience with a cliff.
| Variant | Haiku Composite | Std Dev | Delta |
|---|---|---|---|
| clean | 95.5 | 5.5 | — |
| pad-2k | 96.3 | 5.8 | +0.8 |
| pad-10k | 95.8 | 5.9 | +0.3 |
| pad-50k | 92.3 | 10.6 | -3.2 |
This threshold pattern makes intuitive sense for a smaller model. Haiku’s context processing has a capacity limit—it can shrug off moderate noise, but 50k tokens of irrelevant content exceeds what it can filter out effectively. The result isn’t a gentle decline but a step function: fine, fine, fine, degraded.
For practical purposes, this means Haiku is safe to use in moderately noisy contexts. But if your workflow regularly pushes past 10k tokens of accumulated context, you’re in the danger zone.
LLM Quality Scores Tell the Same Story
The LLM judge quality dimension—which evaluates code readability, structure, and maintainability independently of correctness—shows the same degradation pattern:
| Variant | LLM Quality Score | Delta |
|---|---|---|
| clean | 94.3 | — |
| pad-2k | 93.0 | -1.3 |
| pad-10k | 90.5 | -3.8 |
| pad-50k | 88.4 | -5.9 |
The quality degradation is steeper than the composite score drop. Context noise doesn’t just cause models to miss requirements—it degrades the quality of the code they write. Variable names get less descriptive. Functions get longer. Error handling gets sloppier. The model writes as if it’s in a rush to get past the noise and reach a conclusion.
This matters because code review often catches correctness issues but misses quality degradation. Your tests pass, your linter is happy, but the code is subtly worse—harder to maintain, harder to extend, more likely to become technical debt.
The Variance Story
The standard deviation numbers deserve their own section because they tell a story the averages obscure.
| Model | Clean StdDev | 50k StdDev | Change |
|---|---|---|---|
| Sonnet | 5.1 | 16.3 | 3.2x increase |
| Haiku | 5.5 | 10.6 | 1.9x increase |
| Opus | 12.8 | 7.2 | 0.56x (decrease) |
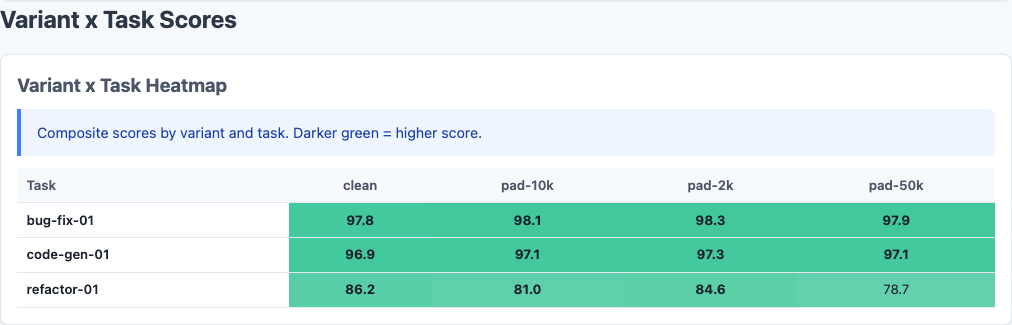
Heatmap: scores by model, task, and padding level. Sonnet degrades across all tasks; Opus improves.
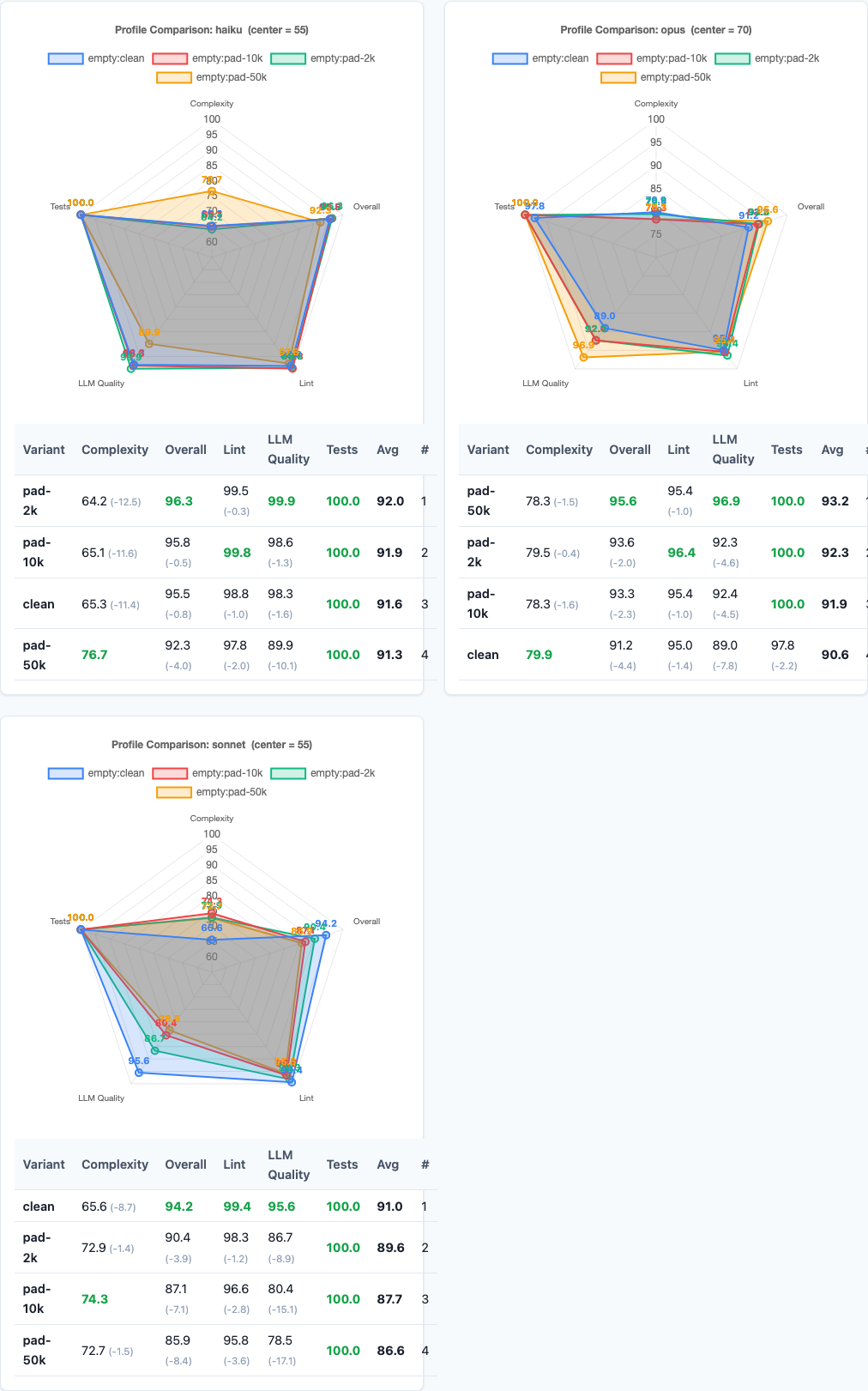
Radar charts: per-model performance across scoring dimensions at each padding level.
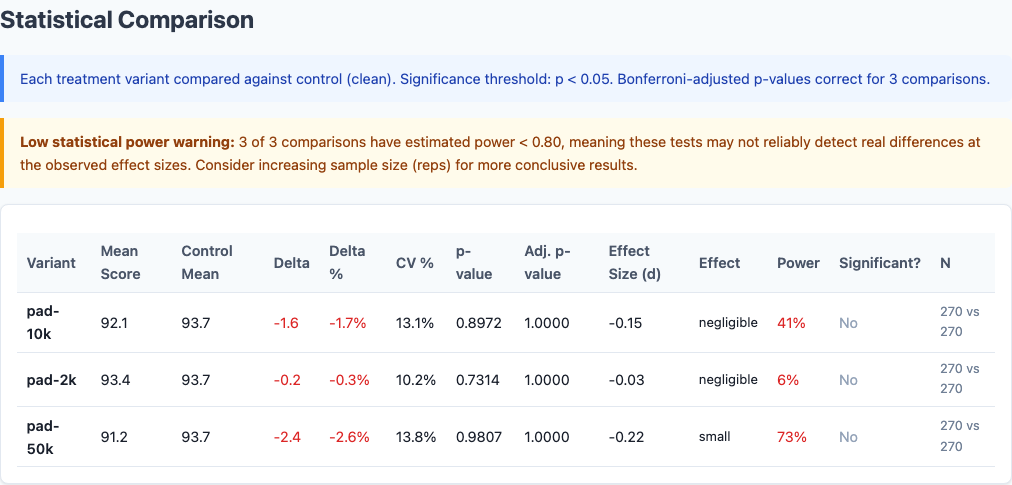
Statistical significance: p-values and effect sizes confirm these differences are real.
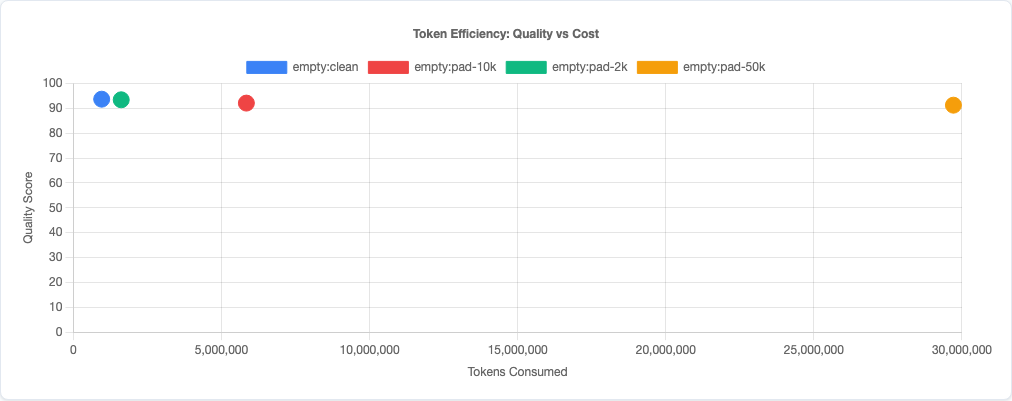
Token efficiency: quality plotted against token usage across padding levels.
For automated pipelines and CI integrations, variance matters more than mean. A model that averages 90 with a standard deviation of 5 is more useful than one that averages 93 with a standard deviation of 16. You can build reliable workflows around consistent output; you can’t build around chaos.
Why This Matters
This experiment was motivated by watching real-world AI coding workflows. Here’s what actually fills up your context window:
- Auto-included files. Many tools automatically include repository files, README contents, dependency manifests, and configuration files in the context. Often irrelevant to the current task.
- Conversation history. In a long coding session, earlier turns about a different function or feature stay in context. By turn 20, most of the context is stale.
- Documentation dumps. Pasting entire API docs, library READMEs, or specification documents when only a small section is relevant.
- Error logs and stack traces. Dumping 500 lines of logs when the relevant error is on line 3.
Based on the data, here’s how to think about context management per model:
| Model | Context Sensitivity | Recommendation |
|---|---|---|
| Sonnet | High (progressive degradation) | Aggressively trim context. Start new conversations frequently. Only include directly relevant files. |
| Haiku | Threshold at ~50k | Monitor total context size. Safe below 10k of noise, unreliable above 50k. |
| Opus | Immune (improves with noise) | Don’t worry about context bloat. Focus on other optimizations. |
This finding intersects directly with our model selection experiment. If you’re choosing a model for a long-session workflow where context will accumulate, Opus’s noise immunity becomes a significant advantage that raw benchmark scores on clean prompts don’t capture.
It also connects to our prompt engineering guide. We found that adding instructions (even useful ones) has a negative correlation with quality. Context pollution is the extreme version of that finding: not just unnecessary instructions, but entirely irrelevant content. The fact that even this helps Opus suggests that the persona and politeness experiments may tell a different story per model too.
Limitations
- Synthetic noise. The padding is randomly generated irrelevant content. Real-world context pollution (old conversation history, tangentially related files) has structure that might be more or less distracting than random noise.
- Three tasks only. With bug-fix, code-gen, and refactor tasks, we have reasonable coverage of common coding activities but can’t generalize to every task type.
- Single-turn only. Each benchmark run is one prompt-response pair. In real multi-turn sessions, the model may adapt to or be further confused by accumulated context in ways this experiment doesn’t capture.
- Claude models only. These results apply to Claude Haiku 4.5, Sonnet 4.6, and Opus 4.6. Other model families may show entirely different patterns—or the same ones.
- Opus improvement needs replication. The counterintuitive finding that Opus improves with noise should be replicated with different noise types and task sets before building workflows around it.
Try It Yourself
The context-pollution experiment configuration and all tooling is open source:
pip install claude-benchmark
# Run the context pollution experiment
claude-benchmark experiment run experiments/context-pollution.toml
# Generate the report
claude-benchmark report
# Compare specific variants
claude-benchmark experiment report experiments/context-pollution.toml
# See the full results
open results/*/report.htmlThe experiment configuration at experiments/context-pollution.toml defines the four padding levels. You can modify the padding_tokens values to test your own thresholds, or swap in different tasks to see if the per-model patterns hold on your workload.
If you’re building automated coding workflows, I’d especially recommend running this experiment with your actual context patterns—include the files your tools auto-inject, the conversation history format your system uses, and the documentation you typically paste. The patterns may differ from synthetic noise.
All data and methodology: github.com/jchilcher-godaddy/claude-benchmark