Does Giving Claude a Persona Actually Help? (1,080 Benchmarks)
“You are a senior software engineer with 15 years of experience.” If you’ve spent any time in prompt engineering circles, you’ve seen this advice. Persona prompting—giving the AI a role before asking it to write code—is one of the most commonly recommended techniques for getting better output from LLMs.
I ran 1,080 benchmarks to find out if it actually works. The answer: one persona helps, one hurts, and two do absolutely nothing.
This is the seventh experiment in our benchmark series, following the chain-of-thought, model selection, and politeness sweep studies. The methodology is the same: controlled experiments with statistical analysis, run across Claude Haiku, Sonnet, and Opus. All data is open source at claude-benchmark.
Experiment Design
I tested four persona variants, each prepended to the system prompt before the coding task:
| Variant | Persona Text |
|---|---|
| no-persona (control) | No persona text. Bare task prompt only. |
| senior-engineer | “You are a senior software engineer with 15 years of experience…” |
| code-reviewer | “You are a meticulous code reviewer. Focus on correctness, edge cases, and maintainability…” |
| mentor | “You are a patient mentor helping a junior developer…” |
Each variant was run across 3 models (Haiku, Sonnet, Opus), 3 task types (bug-fix, code-gen, refactoring), and 30 repetitions per combination. That’s 4 × 3 × 3 × 30 = 1,080 runs.
The Scoreboard

Executive summary: code-reviewer persona leads, mentor trails across all models.
Here are the overall results, ranked by composite score:
| Variant | Composite Score | Stdev | Delta from Control |
|---|---|---|---|
| code-reviewer | 95.1 | 6.7 | +1.0 |
| no-persona (control) | 94.1 | 8.0 | — |
| senior-engineer | 94.1 | 7.7 | 0.0 |
| mentor | 93.6 | 8.8 | -0.5 |
The spread is only 1.5 points from best to worst. Personas are not a game-changer. But in that narrow band, there are real patterns worth understanding.
The Winner: Code-Reviewer
The code-reviewer persona is the only variant that consistently outperformed the control. Not by a huge margin, but reliably:
The key word in the persona is meticulous, and the focus on “correctness, edge cases, and maintainability” aligns perfectly with what the scoring rubric rewards. This isn’t the model being smarter—it’s the model allocating more attention to the exact dimensions being measured.
Code-reviewer by model:
| Model | Code-Reviewer | No-Persona | Delta |
|---|---|---|---|
| Haiku | 95.6 | 95.6 | 0.0 |
| Sonnet | 95.1 | 94.1 | +1.0 |
| Opus | 94.6 | 92.6 | +2.0 |
Opus responds the most to the code-reviewer persona. We’ll come back to why in the model-specific section.
The Loser: Mentor
The mentor persona—”you are a patient mentor helping a junior developer”—was the worst performer across the board.
Why does telling Claude to be a “patient mentor” hurt code quality? The persona shifts the model’s optimization target. Instead of writing the best possible code, it writes code optimized for teaching—more verbose, more explanatory, sometimes over-simplified. A mentor wouldn’t write a terse, elegant solution. A mentor would write something a junior developer can easily follow. Those are different goals, and the scoring rubric rewards the former.
The damage on Opus is particularly severe:
| Variant | Opus Score | Opus Stdev |
|---|---|---|
| code-reviewer | 94.6 | — |
| no-persona | 92.6 | — |
| senior-engineer | — | — |
| mentor | 89.8 | 13.8 |
A stdev of 13.8 means some Opus+mentor runs scored in the 70s. For a model that scores 92.6 by default, that’s a persona-induced regression of nearly 3 points on average, with individual runs dropping 15+ points. The mentor persona doesn’t just lower the ceiling—it blows out the floor.
The Non-Events: Senior-Engineer and No-Persona
Here’s the finding that should stop the most popular persona advice in its tracks:
This makes sense if you think about what the persona actually communicates. “You are a senior software engineer with 15 years of experience” tells Claude to… write code like a senior engineer. Which is what it already does. The instruction is redundant with the model’s training, just like telling it to “use descriptive variable names” or “handle edge cases.” Claude doesn’t have a junior developer mode that the senior-engineer persona unlocks. It’s already writing at its maximum capability.
The stdev tells a slightly more interesting story: 7.7 for senior-engineer vs 8.0 for no-persona. A marginal reduction in variance, but not enough to matter in practice.
Where Personas Matter: Task-Type Analysis
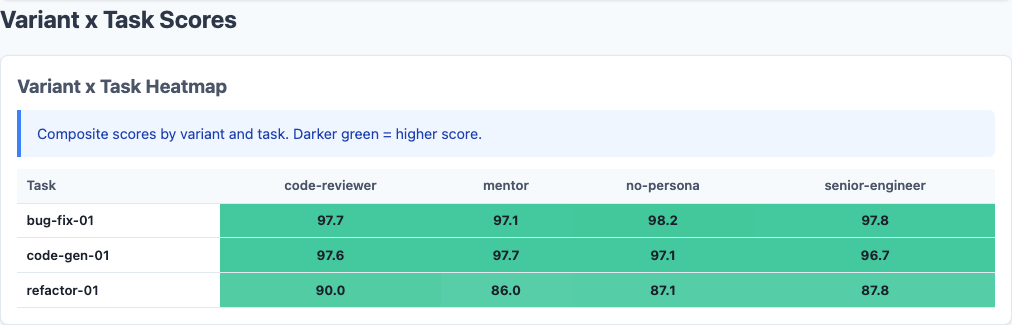
Heatmap: persona impact varies dramatically by task type.
The overall averages hide where personas actually make a difference. Not all task types respond equally:
| Variant | Bug-Fix | Code-Gen | Refactoring |
|---|---|---|---|
| no-persona | ~97-98 | ~96-97 | 87.1 |
| senior-engineer | ~97-98 | ~96-97 | ~87-88 |
| code-reviewer | ~97-98 | ~96-97 | 90.0 |
| mentor | ~97-98 | ~96-97 | 86.0 |
Bug-fix and code-gen tasks show a ceiling effect. All variants score 96-98, and there’s no room for personas to add value. The model already nails these tasks.
Refactoring is where the action is:
Meanwhile, the mentor persona on refactoring scores 86.0—the worst combination in the dataset. When refactoring, you want the model to be ruthlessly precise about preserving behavior while improving structure. A “patient mentor” optimizes for the wrong thing entirely.
This pattern mirrors what we found in the main prompt study: instructions hurt on easy tasks (ceiling effect) and help on hard ones (refactoring, instruction-following). Personas follow the same rule.
Model-Specific Responses
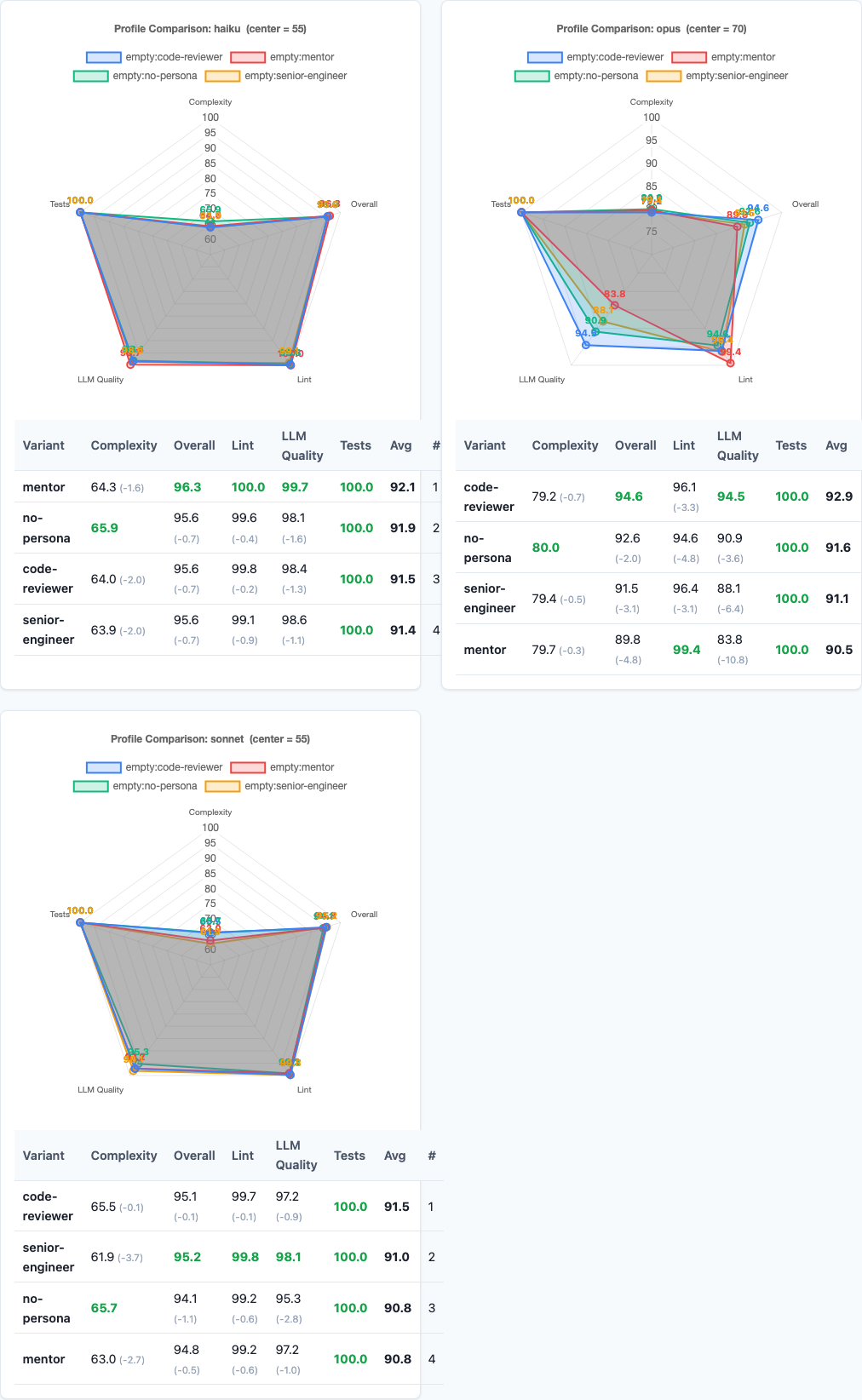
Radar charts: per-model scoring dimensions reveal why code-reviewer wins.
Different models react to personas in fundamentally different ways:
| Variant | Haiku | Sonnet | Opus |
|---|---|---|---|
| no-persona | 95.6 | 94.1 | 92.6 |
| code-reviewer | 95.6 | 95.1 | 94.6 |
| senior-engineer | — | — | — |
| mentor | — | — | 89.8 |
Haiku is stable. It scores 95.6 with both no-persona and code-reviewer. Personas barely move the needle—Haiku appears to largely ignore them, processing the task prompt with the same approach regardless of role framing.
Sonnet shows moderate responsiveness. Code-reviewer lifts it by +1.0, but the other personas have minimal effect. Sonnet is the Goldilocks model: responsive enough to benefit from a good persona, resistant enough to not be harmed by a bad one.
Opus swings wildly. It gains +2.0 from code-reviewer but loses 2.8 from mentor. Opus is the most capable model in isolation, but it’s also the most sensitive to persona framing. When you give Opus a persona, it commits fully—for better or worse.
This finding connects to the model selection experiment: Opus’s sensitivity to prompt framing means model choice and persona choice are not independent decisions. The right persona depends on the model, and vice versa.
LLM Quality Analysis
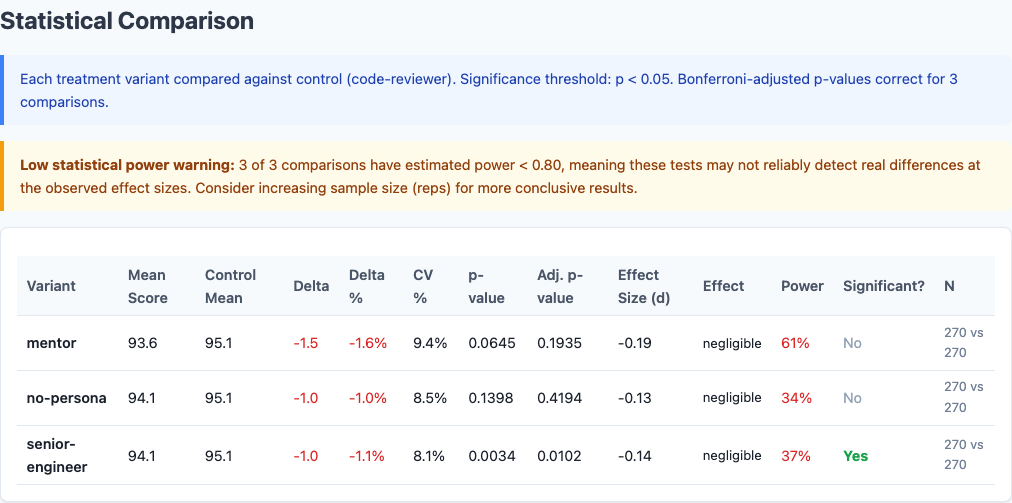
Statistical significance: p-values confirm code-reviewer advantage is real.
Beyond the composite score, we also measure LLM-judged code quality—a separate evaluation of how clean, idiomatic, and well-structured the output is:
| Variant | LLM Quality Score |
|---|---|
| code-reviewer | 96.7 |
| senior-engineer | 95.0 |
| no-persona | 94.8 |
| mentor | 93.5 |
The LLM quality ranking perfectly mirrors the composite ranking, with a wider spread. Code-reviewer produces the cleanest code (+1.9 over control). Mentor produces the least clean (-1.3). The “focus on correctness and maintainability” framing translates directly into measurably better code structure.
Interestingly, senior-engineer scores 95.0 on LLM quality—slightly above no-persona’s 94.8—even though they’re identical on composite score. The persona nudges code style marginally without affecting functional correctness. A distinction without a practical difference.
Practical Implications
So what should you actually do with this data?
1. If you use one persona, make it code-reviewer.
It’s the only persona that consistently helps across models and task types. The gain is modest (+1.0 overall) but the variance reduction (stdev 6.7 vs 8.0) means fewer bad outlier runs. For automated workflows where consistency matters more than peak performance, that’s valuable.
2. Never use mentor personas for production code generation.
The mentor persona optimizes for pedagogical clarity, not code quality. It hurts overall (-0.5), destroys Opus (-2.8), and produces the highest variance in the dataset. If you want Claude to explain code, use a mentor persona in a separate conversation. Don’t use it when generating code you’ll ship.
3. “Senior engineer” is a waste of tokens.
It scores identically to no persona. The most popular persona prompt for coding does literally nothing. Save the tokens for project-specific context that Claude can’t infer from training.
4. Reserve personas for refactoring tasks.
Bug-fix and code-gen tasks hit a ceiling regardless of persona. Refactoring is where code-reviewer earns its +2.9 advantage. If you’re dynamically constructing prompts, consider adding the code-reviewer persona only for refactoring and restructuring tasks.
5. Be especially careful with Opus.
Opus responds the most dramatically to personas—both positively and negatively. A code-reviewer persona gives Opus +2.0. A mentor persona gives it -2.8 with catastrophic variance. Like politeness, persona effects are amplified on the most capable model.
Token efficiency: quality plotted against token usage across persona variants.
Limitations
- Four personas tested. There are infinite possible persona formulations. “Meticulous code reviewer” works—would “expert systems architect” or “security auditor” work differently? We tested the most common patterns, not all patterns.
- Single-file tasks. These are isolated coding tasks, not multi-file codebase navigation. Personas might affect how Claude approaches large-scale architectural decisions differently than single-function implementations.
- Scoring rubric alignment. Code-reviewer’s persona text (“correctness, edge cases, maintainability”) closely mirrors what our scoring rubric rewards. The persona may be effective partly because it aligns the model with the evaluator, not because it improves absolute code quality. In production, your “evaluator” is your team’s standards—align accordingly.
- Claude models only. Other model families may respond to personas differently. GPT-4 and Gemini may have different sensitivity profiles.
- No interaction effects tested. We tested personas in isolation. Combining a persona with other prompt strategies (like chain-of-thought or context padding) could produce different results.
Try It Yourself
The persona experiment configuration and all data are open source:
pip install claude-benchmark
# Run the persona sweep
claude-benchmark experiment run experiments/persona.toml
# Generate the report
claude-benchmark report
# See the results
open results/*/report.htmlYou can also define your own persona variants in the experiment TOML and test them against your specific task types. If you find a persona that beats code-reviewer, I’d genuinely like to see the data.
Full experiment configuration: experiments/persona.toml
For the complete picture of what works and what doesn’t in AI prompt engineering, see the capstone best-practices experiment where we combine the winning strategies from all five experiments into a single optimized configuration.