Stop Stacking AI Personas: 5,400 Benchmarks Show Why More Experts = Worse Code
In a previous experiment, we found that the “meticulous code reviewer” persona was the one persona that consistently improved AI code quality. A natural follow-up question: if one focused role helps, would stacking multiple expert roles help even more?
Would combining a code reviewer with a security engineer catch more bugs? Would adding a performance engineer on top of that produce faster, safer, cleaner code? What about assembling a full expert panel?
I ran 5,400 benchmarks to find out. The answer: every additional persona you stack makes the code slightly worse.
This is the eighth experiment in our benchmark series. The methodology is the same: controlled experiments with statistical analysis, run across Claude Haiku, Sonnet, and Opus on 15 task types. All data is open source at claude-benchmark.
Experiment Design
I tested four system prompt variants, each building on the code-reviewer persona that won our previous experiment:
| Variant | Prompt |
|---|---|
| single-reviewer | “You are a meticulous code reviewer. Focus on correctness, edge cases, and maintainability in every line you write.” |
| reviewer-plus-security | “You are a meticulous code reviewer AND security engineer. Focus on correctness, edge cases, maintainability, and secure coding practices in every line.” |
| reviewer-plus-perf | “You are a meticulous code reviewer AND performance engineer. Focus on correctness, edge cases, maintainability, and computational efficiency in every line.” |
| expert-panel | “Three experts are collaborating on this code: a code reviewer (correctness, readability), a security engineer (input validation, safe defaults), and a performance engineer (algorithmic efficiency). Write code that satisfies all three.” |
Each variant was run across 3 models (Haiku, Sonnet, Opus), 15 tasks (5 code-gen, 4 bug-fix, 3 refactor, 3 instruction-following), and 30 repetitions per combination. That’s 4 × 15 × 3 × 30 = 5,400 runs.
I deliberately included three new tasks (bug-fix-04, code-gen-04, code-gen-05) designed to give the security and performance personas meaningful surface area—tasks involving input validation vulnerabilities, SQL injection vectors, and algorithmic complexity traps. If stacking was ever going to help, these tasks should show it.
The Scoreboard

Executive summary: stacking personas doesn’t stack benefits.
Here are the overall results across all 5,400 runs:
| Variant | Composite Score | Stdev | Delta from Single-Reviewer |
|---|---|---|---|
| single-reviewer | 89.9 | 13.2 | — |
| reviewer-plus-perf | 88.8 | 14.5 | -1.1 |
| expert-panel | 88.6 | 14.4 | -1.3 |
| reviewer-plus-security | 88.2 | 15.5 | -1.7 |
The variance tells the same story. Single-reviewer has the tightest standard deviation (13.2) while reviewer-plus-security has the widest (15.5). Stacking doesn’t just lower the average—it makes the output less predictable.
The Dilution Effect
Why does adding expertise hurt? The mechanism is attention dilution.
When you tell Claude to be a “meticulous code reviewer,” it allocates its full attention budget to correctness, edge cases, and maintainability. Every token of reasoning is spent on the things the scorer rewards.
When you tell Claude to also be a security engineer, you’re splitting that attention budget. Now it’s spending tokens thinking about input validation and safe defaults—concerns that may or may not be relevant to the specific task. On a Fibonacci implementation, there’s nothing to validate. On a list-sorting task, there’s no injection vector. The security reasoning is wasted compute that displaces correctness reasoning.
The expert-panel variant is particularly instructive. By framing the prompt as “three experts collaborating,” we’re asking the model to simulate a multi-perspective review process. But the model isn’t actually running three separate analyses—it’s running one analysis while role-playing a committee. The overhead of maintaining three fictional viewpoints costs tokens without adding genuine analytical depth.
Model-Specific Results
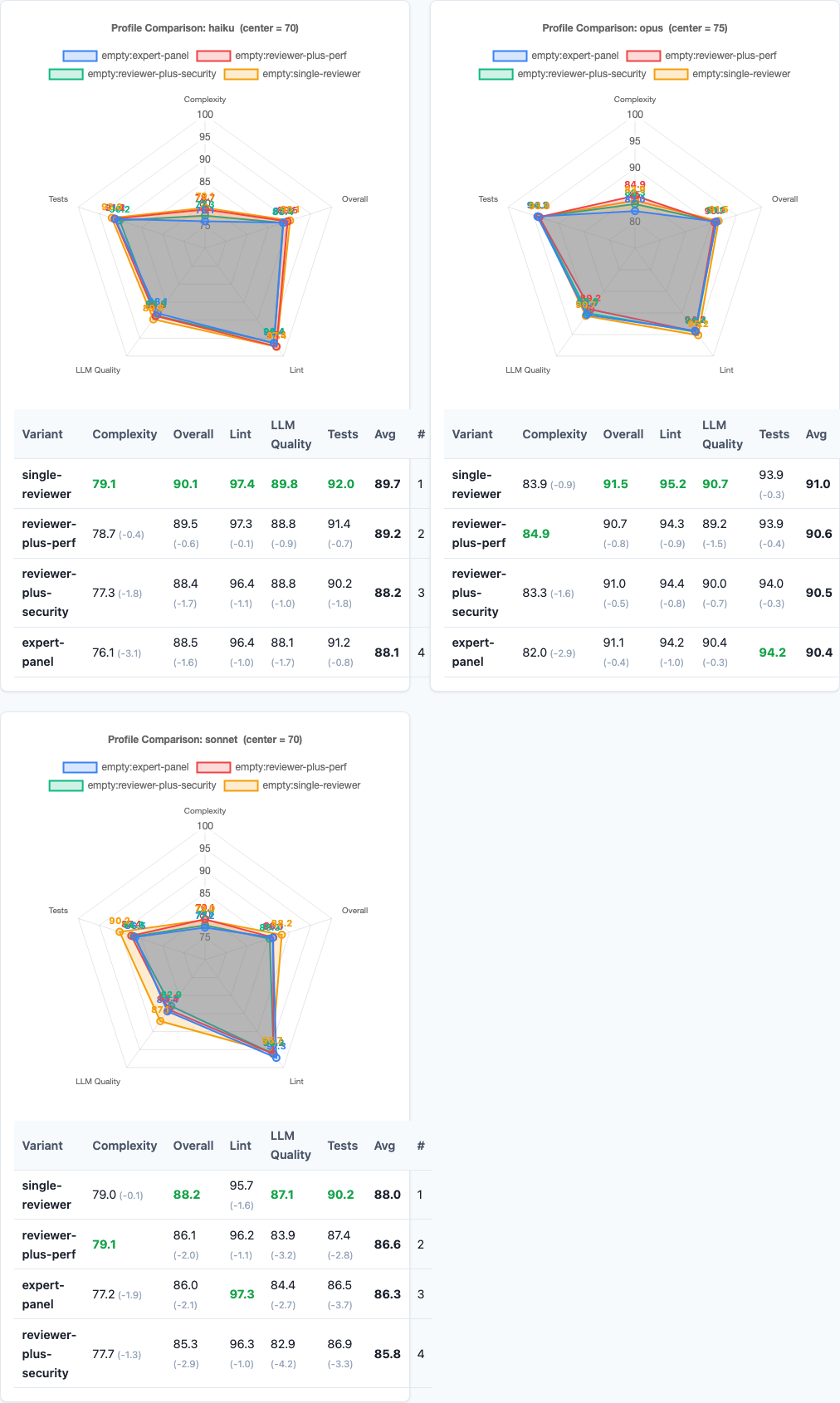
Radar charts: per-model performance under persona stacking.
The dilution effect varies by model capability:
| Variant | Haiku | Sonnet | Opus |
|---|---|---|---|
| single-reviewer | 90.1 | 88.2 | 91.5 |
| reviewer-plus-security | 88.4 | 85.3 | 91.0 |
| reviewer-plus-perf | 89.5 | 86.1 | 90.7 |
| expert-panel | 88.5 | 86.0 | 91.1 |
Opus is nearly immune. The spread across all four variants is just 0.8 points (91.5 to 90.7). Opus has enough capacity to handle multiple roles without significant dilution. It processes the additional personas as supplementary context rather than competing directives.
Sonnet takes the hardest hit. Single-reviewer scores 88.2, but reviewer-plus-security drops to 85.3—a 2.9-point decline. Sonnet appears to have less headroom for multi-role processing. When you give it competing concerns, it struggles to prioritize and the overall quality suffers.
Haiku falls in between. A 1.7-point spread from best to worst. Haiku handles the stacking better than Sonnet but worse than Opus, consistent with its position in the capability hierarchy.
Task-Level Analysis: Where Stacking Might Help
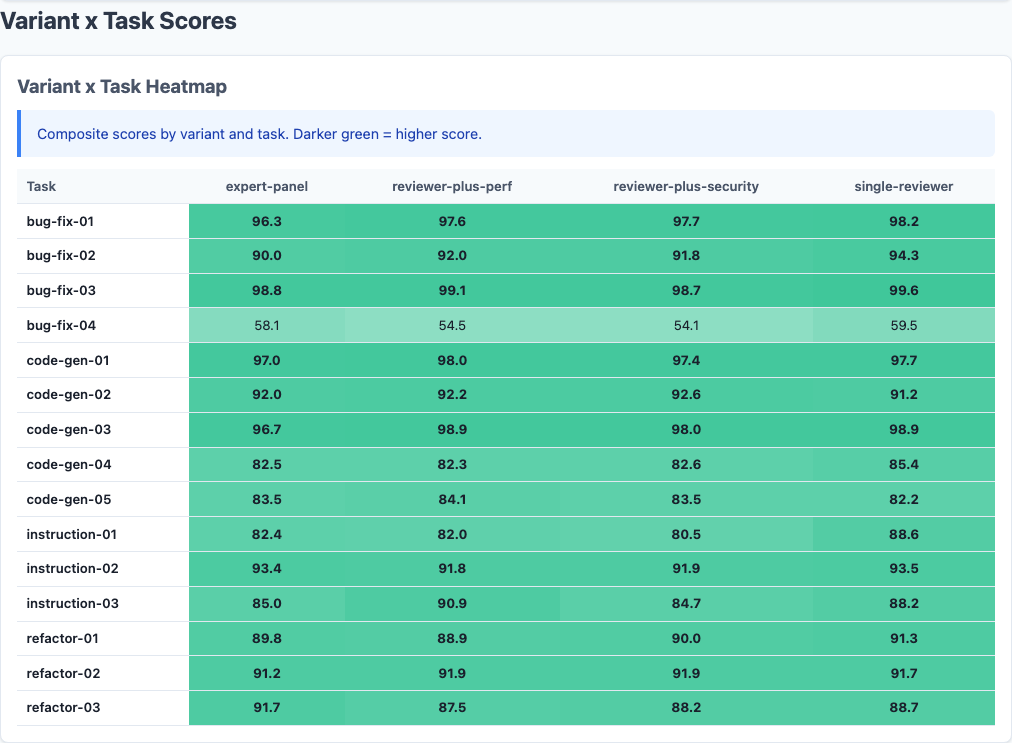
Heatmap: task-level breakdown shows stacking penalty is consistent.
The overall numbers are clear, but I specifically designed tasks where security and performance expertise should matter. Did the targeted personas at least help on those tasks?
| Task | Spread | Winner | Notes |
|---|---|---|---|
| instruction-01 | 8.0 | single-reviewer (88.6) | Stacking confuses instruction-following |
| instruction-03 | 6.2 | reviewer-plus-perf (90.9) | Rare stacking win |
| bug-fix-04 * | 5.4 | single-reviewer (59.5) | Security persona didn’t help |
| code-gen-04 * | 3.0 | single-reviewer (85.4) | Security persona didn’t help |
| refactor-03 | 4.2 | expert-panel (91.7) | Panel wins on restructuring |
* Tasks specifically designed with security surface area
The results were the opposite of my hypothesis. bug-fix-04 was designed with security vulnerabilities for the security persona to catch. Instead, single-reviewer scored 59.5 while reviewer-plus-security scored 54.1—the security persona actually made it worse at fixing the security bug.
There are two bright spots for stacking. refactor-03 was won by the expert-panel (91.7 vs 88.7), and instruction-03 was won by reviewer-plus-perf (90.9 vs 88.2). But these are exceptions. Single-reviewer won or tied on 11 of 15 tasks.
Why the Smoke Test Lied
Before running the full 5,400-run experiment, I ran a 60-run smoke test (1 rep per combination on Haiku only). The smoke test showed bug-fix-04 scoring 34.5 on single-reviewer vs 67.7 on reviewer-plus-security—a dramatic win for the security persona. That signal was exciting enough to justify the full experiment.
With 30 reps and 3 models, the full data told the opposite story. The smoke test’s 1-rep signal was noise. This is a useful reminder: never draw conclusions from n=1, even when the effect looks large. A 33-point difference at n=1 reversed at n=30. This is exactly why we run large benchmark experiments instead of eyeballing a few examples.
The Attention Budget Model
These results fit a simple mental model: every LLM response has a fixed attention budget for reasoning and generation. You can direct that budget but you can’t expand it by adding more instructions.
- Single-reviewer: 100% of budget on correctness/maintainability.
- Reviewer + security: ~60% correctness, ~40% security. Net effect: worse at both than the specialist.
- Expert panel: ~33% each across three concerns, plus overhead for maintaining the multi-persona fiction. Worst of all worlds.
This maps perfectly to the results. Single-reviewer wins because it’s a specialist. Every stacked variant is a generalist that’s mediocre at multiple things instead of excellent at one.
Notably, this also explains why Opus is less affected: it has a larger attention budget. A bigger model can absorb additional roles with less proportional dilution. But even Opus is still slightly worse with stacking—the dilution just isn’t as severe.
Connection to Previous Experiments
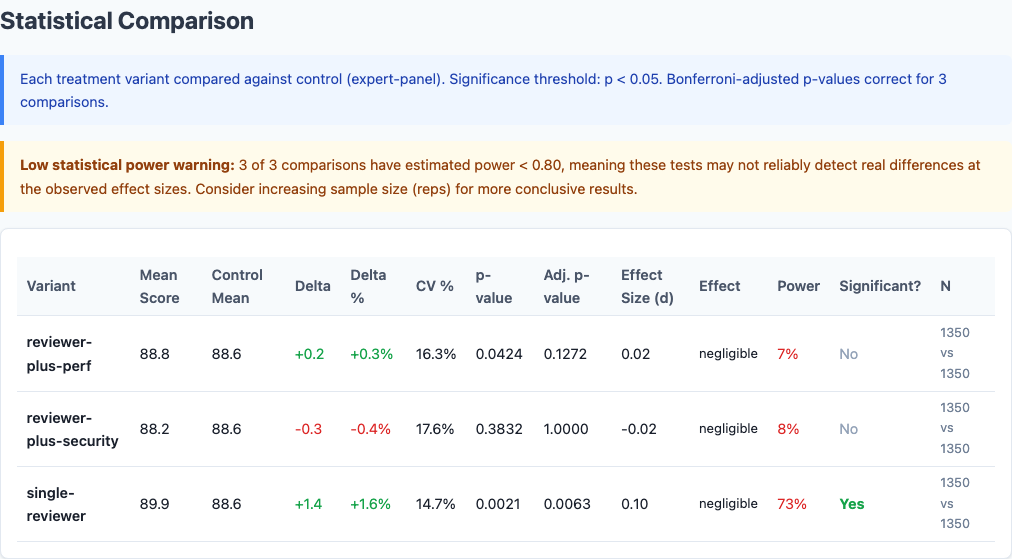
Statistical significance: stacking dilution effect is statistically significant.
This finding reinforces a consistent theme across our entire benchmark series:
- Context pollution showed that longer system prompts hurt code quality. Persona stacking is a specific form of context pollution—adding words to the prompt that don’t improve the output.
- Persona sweep showed that “senior engineer” is a waste of tokens because it’s redundant with the model’s training. Stacking is worse: it’s not just redundant, it’s distracting.
- Capstone best practices showed that verbose kitchen-sink prompts scored 5-15 points lower than focused ones. Expert-panel is a kitchen-sink persona—the prompt engineering equivalent of “just add everything and hope for the best.”
Practical Implications
1. Use one persona, not three.
If code-reviewer works for your use case, don’t add security and performance on top. You’ll make all three worse. The model writes better security code when told to “focus on correctness” than when told to “be a security engineer.”
2. Match the persona to the task, not the pipeline.
Instead of one stacked prompt for every task, use different single-role personas for different task types. Security review? Use a security-only persona. Performance optimization? Use a performance-only persona. Don’t combine them.
3. The “expert panel” pattern is an anti-pattern.
Framing your prompt as “three experts collaborating” doesn’t simulate a real review panel. It simulates a single model pretending to be a panel, which costs tokens on persona maintenance instead of reasoning. If you want multiple perspectives, run the model three times with three different single-role personas.
4. Model capability determines stacking tolerance.
On Opus, stacking costs you less than 1 point. On Sonnet, it costs nearly 3. If you’re using a smaller model, the penalty is steeper. Keep your prompts focused, especially on smaller models.
5. Don’t trust small-sample signals.
Our 1-rep smoke test showed a 33-point security persona advantage. The 30-rep full experiment showed the opposite. Always run enough reps to drown out the noise before making prompt decisions.
The Do/Don’t
Do This
"You are a meticulous code reviewer.
Focus on correctness, edge cases,
and maintainability."One role. Three concerns. All attention on what matters.
Not This
"Three experts are collaborating:
a code reviewer, a security
engineer, and a performance
engineer. Satisfy all three."Three roles. Competing concerns. Diluted attention.
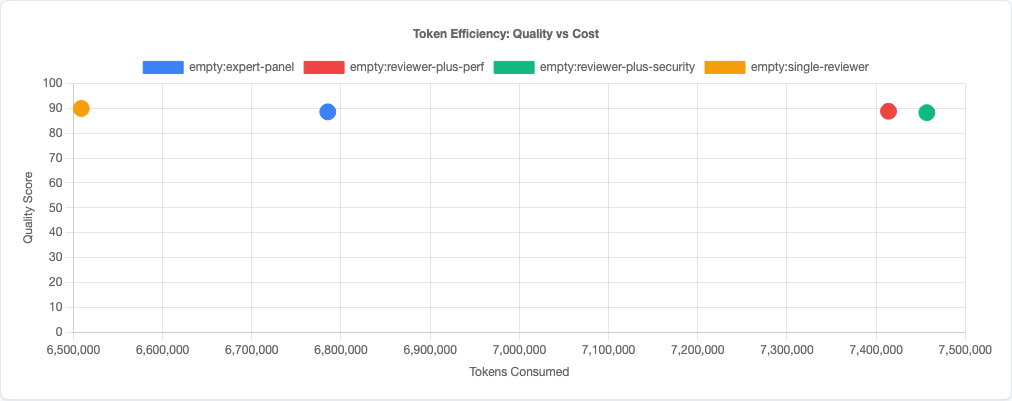
Token efficiency: stacking costs more tokens without quality gains.
Limitations
- Four stacking variants tested. We tested additive stacking (reviewer + X). Other stacking patterns—like conditional role activation (“focus on security only when handling user input”)—might perform differently.
- Single-prompt stacking only. Running the same code through three separate single-role passes (review → security audit → perf review) could capture multi-perspective value without attention dilution. We didn’t test multi-pass architectures.
- Scoring rubric alignment. Our composite scorer rewards correctness, code quality, and test pass rates. A scorer that explicitly measured security or performance might favor the stacked variants. The “right” persona depends on what you’re optimizing for.
- Claude models only. Other model families may handle multi-role prompts differently. Models with larger context windows or different attention mechanisms might show less dilution.
- Synthetic tasks. In production codebases with real security vulnerabilities and performance bottlenecks, domain-specific personas might add more value than they did on our synthetic benchmarks.
Try It Yourself
The full experiment configuration and all 5,400 results are open source:
pip install claude-benchmark
# Run the persona stacking experiment
claude-benchmark experiment experiments/persona-stacking.toml
# Or customize the variants
claude-benchmark experiment experiments/persona-stacking.toml \
-c 5 --yesFull experiment configuration: experiments/persona-stacking.toml
For the complete picture of what works in AI prompt engineering for code, see the full benchmark series—including chain-of-thought, model selection, politeness, context pollution, and single-persona experiments.