Telling AI to Write 95/100 Code Doesn’t Make It Write 95/100 Code (5,760 Benchmarks)
“Top developers score 95+/100 on this task.” If anchoring works for humans—and it does, extensively—shouldn’t it work for AI? Set a high bar, prime the model with quality expectations, and watch the output improve.
I ran 5,760 benchmarks to test this. Four anchoring variants: high standards, negative warnings, Google-grade quality bars, and a bare baseline. None of them moved the needle. The score spread across all four variants was 1.2 points. Zero statistically significant differences. AI models have a quality set point, and anchor text doesn’t change it.
This is the thirteenth experiment in our benchmark series, following the chain-of-thought, context pollution, model selection, politeness sweep, persona sweep, and step-back studies. All data is open source at claude-benchmark.
Experiment Design
I tested four anchoring variants, each prepended to the system prompt:
| Variant | Anchoring Text |
|---|---|
| high-anchor (control) | “Top developers score 95+/100 on tasks like this. Aim for that standard.” |
| no-anchor | No anchoring text. Bare baseline prompt. |
| negative-anchor | “Most developers make 2 mistakes on tasks like this. Avoid them.” |
| quality-bar | “This code must pass rigorous review at Google/Stripe. Meet that bar.” |
Each variant was run across:
- 3 models: Haiku, Sonnet, Opus
- 16 tasks: 5 code-gen, 4 bug-fix, 4 refactor, 3 instruction-following
- 30 repetitions per model-task-variant combination
That’s 4 variants × 3 models × 16 tasks × 30 reps = 5,760 runs.
The Scoreboard

Executive summary: overall performance across all tested variants.
Here are the overall results:
| Variant | Score | Stdev | CV | Delta | p-value |
|---|---|---|---|---|---|
| no-anchor | 89.4 | 11.8 | 13.2% | +0.1 | 0.46 |
| high-anchor (control) | 89.3 | 11.4 | 12.8% | — | — |
| negative-anchor | 88.6 | 11.9 | 13.4% | -0.7 | 0.07 |
| quality-bar | 88.2 | 15.0 | 17.0% | -1.1 | 0.76 |
The bare baseline (no-anchor) is indistinguishable from the high-anchor control. The negative-anchor trends slightly negative but doesn’t clear significance. The quality-bar variant is the worst performer, with the highest variance.
The Variance Story
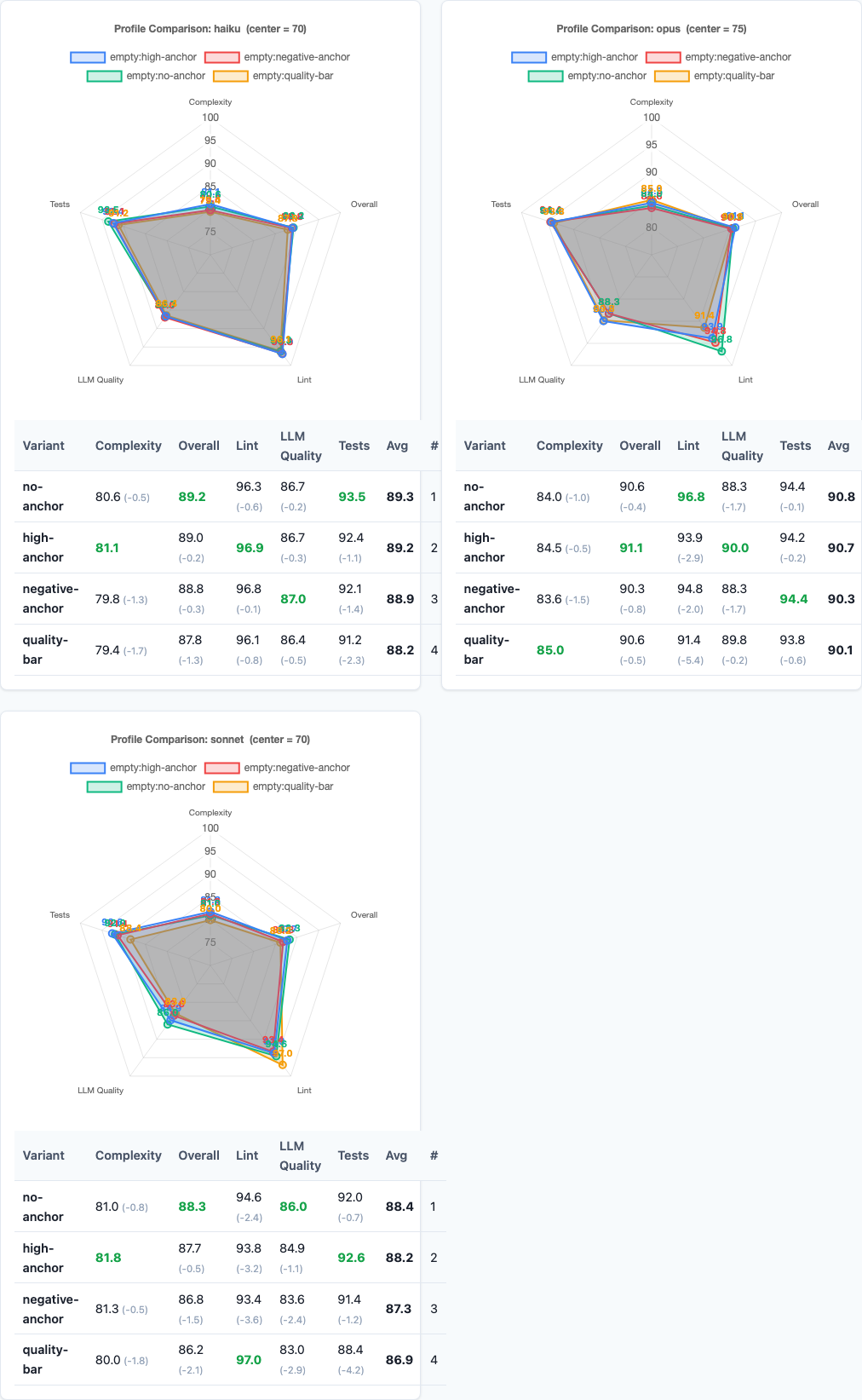
Radar charts: multi-dimensional performance comparison.
While scores barely move, consistency does:
| Variant | Stdev | CV (Coefficient of Variation) |
|---|---|---|
| high-anchor | 11.4 | 12.8% |
| no-anchor | 11.8 | 13.2% |
| negative-anchor | 11.9 | 13.4% |
| quality-bar | 15.0 | 17.0% |
This mirrors what we found in the context pollution experiment: adding expectations that the model can’t consistently meet just introduces noise. The model doesn’t rise to the challenge—it thrashes.
Model-Specific Results
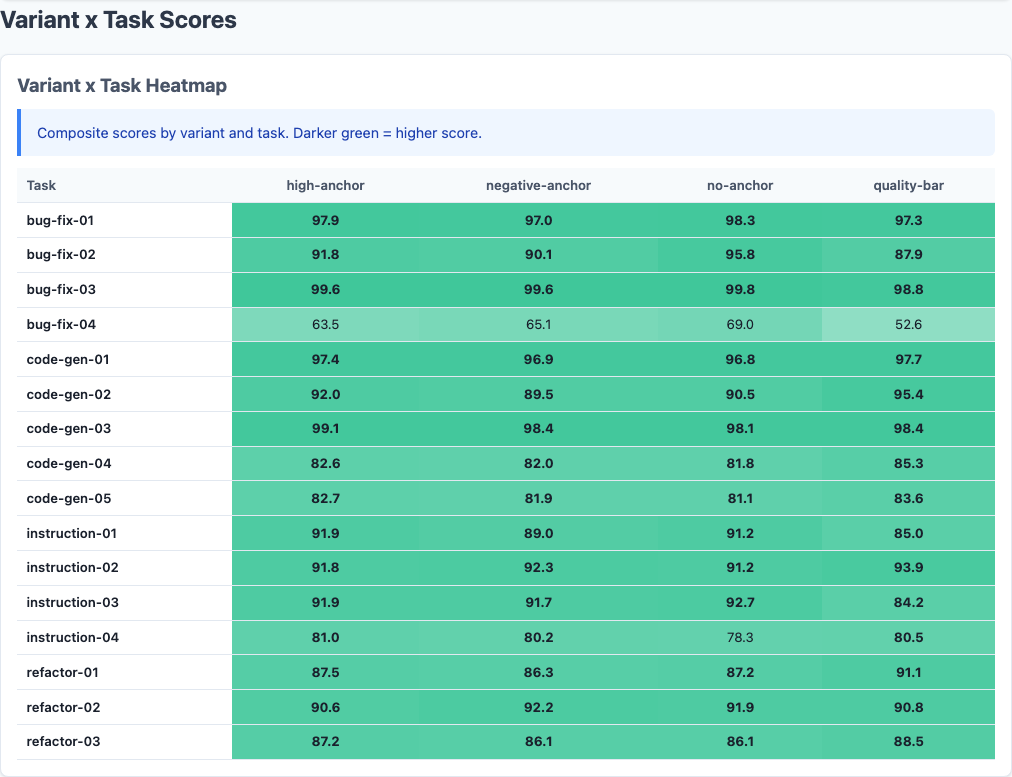
Heatmap: detailed performance breakdown across dimensions.
Do different models respond differently to anchoring?
| Model | No-Anchor | High-Anchor | Negative-Anchor | Quality-Bar |
|---|---|---|---|---|
| Haiku | 86.7 | 86.5 | 86.1 | 85.3 |
| Sonnet | 90.2 | 90.3 | 89.6 | 89.4 |
| Opus | 91.3 | 91.1 | 90.1 | 89.9 |
All three models are essentially flat across anchoring variants. Haiku, Sonnet, and Opus all ignore the anchor text. The quality-bar variant is consistently the worst performer across all models, but the differences are small and non-significant.
This is the opposite of the persona experiment, where Opus swung wildly based on role framing. Anchoring is fundamentally different: personas change the optimization target, but anchors just set expectations—and expectations don’t change what the model is capable of.
Task-Type Breakdown
Maybe anchoring helps on specific task types?
| Task Type | No-Anchor | High-Anchor | Negative-Anchor | Quality-Bar |
|---|---|---|---|---|
| Code-Gen | 91.8 | 91.7 | 91.2 | 90.8 |
| Bug-Fix | 88.9 | 88.7 | 88.4 | 88.0 |
| Refactoring | 87.5 | 87.3 | 86.9 | 85.7 |
| Instruction | 90.1 | 89.9 | 89.0 | 88.3 |
No task type shows meaningful sensitivity to anchoring. Code-gen, bug-fix, refactoring, and instruction tasks all trend slightly negative as anchor intensity increases, but the differences are within noise.
Refactoring tasks show the largest drop for quality-bar (87.5 → 85.7), which makes sense: refactoring is already the hardest task type, and demanding “Google-grade” quality on a task the model struggles with just makes it worse.
Why Anchoring Doesn’t Work
This is the key insight: AI models already operate at their capability ceiling.
This is different from human anchoring. When you tell a human developer “most people make 2 mistakes,” they adjust their effort level. AI doesn’t have an effort level to adjust. It’s always operating at maximum capability for the given prompt and task. Anchors are noise.
Practical Implications
1. Don’t set quality expectations in prompts.
Telling the model to “write production-grade code” or “aim for 95/100 quality” wastes tokens and doesn’t change output. The model is already writing the best code it can. Save the tokens for relevant context.
2. Avoid negative framing.
The negative-anchor variant (“most developers make 2 mistakes”) trends negative without crossing significance. There’s no upside and potential downside. Don’t prime the model with failure modes—just state the task.
3. Never demand “Google/FAANG-grade quality.”
The quality-bar variant has the worst score (88.2) and the highest variance (stdev 15.0, CV 17.0%). Demanding impossibly high standards makes output LESS consistent, not better. If you need higher quality, use a better model—don’t try to motivate the current model with aspirational language.
4. Anchoring is a human bias, not an AI feature.
Humans respond to anchors because we have variable effort levels and adjust based on perceived difficulty. AI models don’t. They operate at their capability ceiling regardless of the expectations you set. Techniques from human psychology don’t transfer to LLMs.
Token efficiency: quality vs cost tradeoff.
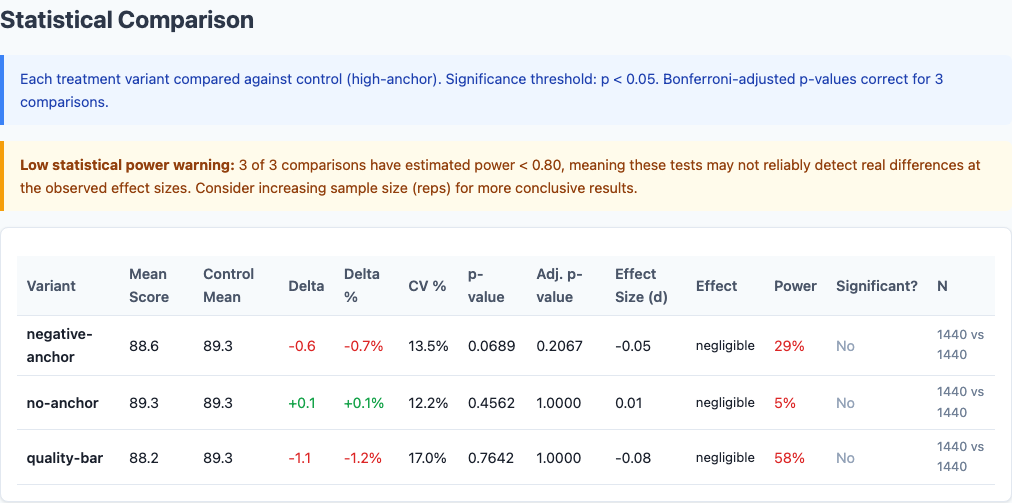
Statistical significance analysis.
Limitations
- Four anchoring variants tested. We tested high anchors, negative anchors, quality bars, and no anchor. There may be other formulations (low anchors, specific numeric targets) that behave differently, though the pattern across all variants suggests anchoring itself is ineffective.
- Single-file tasks. These are isolated coding tasks. Anchoring might affect how the model approaches multi-file architectural decisions differently than single-function implementations.
- Claude models only. Other model families (GPT-4, Gemini, etc.) may respond to anchoring differently. But the consistency across Haiku, Sonnet, and Opus suggests this is a fundamental property of how LLMs work.
- No combined strategies tested. We didn’t test anchoring combined with other prompt strategies (like personas or chain-of-thought). Interaction effects could exist.
- Scoring rubric ceiling. Our rubric has a maximum score of 100. If anchoring affects aspirations beyond the rubric’s measurement range, we wouldn’t detect it. But given that no variant even approached the ceiling, this seems unlikely.
Try It Yourself
The anchoring experiment configuration and all data are open source:
pip install claude-benchmark
# Run the anchoring experiment
claude-benchmark experiment run experiments/anchoring.toml
# Generate the report
claude-benchmark report
# See the results
open results/*/report.htmlYou can also define your own anchoring variants in the experiment TOML and test them against your specific task types. If you find an anchoring strategy that actually moves quality, I’d like to see the data.
Full experiment configuration: experiments/anchoring.toml
For the complete picture of what works and what doesn’t in AI prompt engineering, see the capstone best-practices experiment where we combine the winning strategies from all experiments into a single optimized configuration.