Step-Back Prompting Doesn’t Improve AI Code (4,050 Benchmarks)
Google DeepMind published a paper on “step-back prompting”—asking LLMs to identify general principles or common pitfalls before solving a problem. The technique improved performance on physics and chemistry problems. So naturally, everyone assumed it would work for code too.
It doesn’t. I ran 4,050 benchmarks across 3 Claude models and 15 diverse coding tasks. Neither step-back variant improved code quality. Both hurt slightly. One was statistically insignificant (p=0.90). The other trended negative but didn’t cross the significance threshold (p=0.19). Neither cleared the negligible effect size bar.
This is the twelfth experiment in our benchmark series, following the chain-of-thought, context pollution, model selection, politeness sweep, and persona sweep studies. All data is open source at claude-benchmark.
Experiment Design
I tested three variants of step-back prompting against a direct control:
| Variant | Prompting Strategy |
|---|---|
| direct/control | Bare task prompt with no meta-cognitive framing. |
| step-back-principles | “Before solving, identify general programming principles and patterns relevant to this task.” |
| step-back-pitfalls | “Before solving, list 2-3 common mistakes developers make on tasks like this.” |
Each variant was run across:
- 3 models: Haiku, Sonnet, Opus
- 15 tasks: 5 code-gen, 4 bug-fix, 3 refactor, 3 instruction-following
- 30 repetitions per model-task-variant combination
That’s 3 variants × 3 models × 15 tasks × 30 reps = 4,050 runs.
The Scoreboard

Executive summary: overall performance across all tested variants.
Here are the overall results:
| Variant | Score | Stdev | Delta | p-value | Effect Size (d) |
|---|---|---|---|---|---|
| direct/control | 89.7 | 12.4 | — | — | — |
| step-back-principles | 89.5 | 12.8 | -0.2 | 0.90 | -0.01 |
| step-back-pitfalls | 89.2 | 12.6 | -0.5 | 0.19 | -0.04 |
The principles variant is essentially identical to the control. The pitfalls variant trends negative but doesn’t clear the significance threshold. Neither is worth the token cost.
Task-Type Breakdown
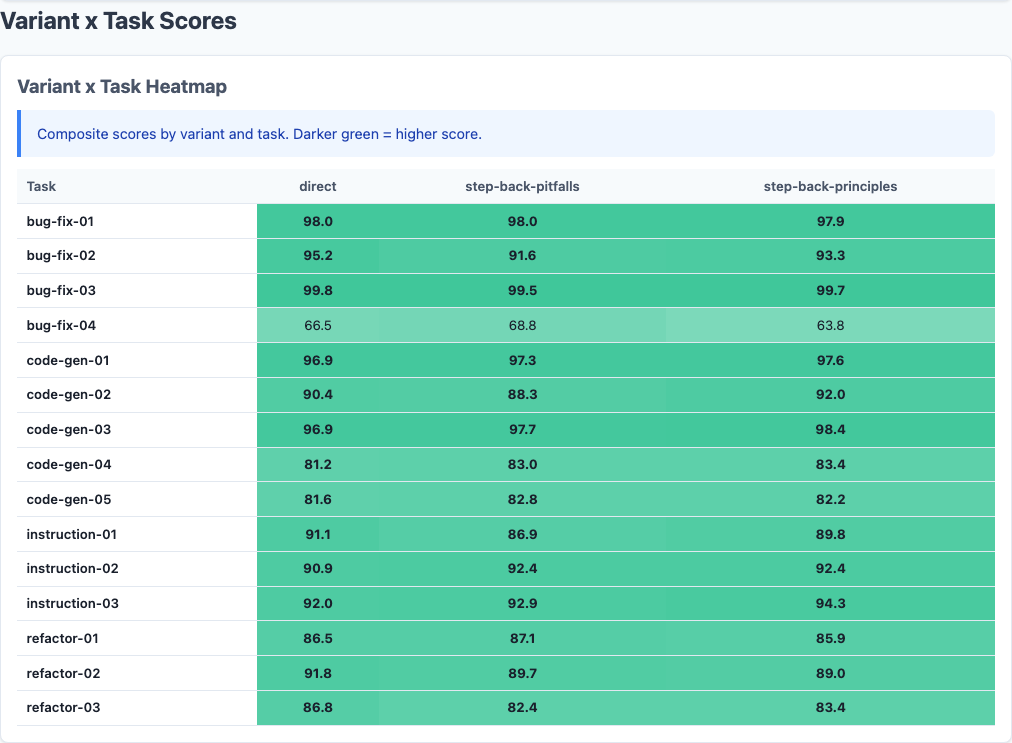
Heatmap: detailed performance breakdown across dimensions.
Maybe step-back helps on certain task types? Here’s the breakdown:
| Task Type | Direct | Principles | Pitfalls |
|---|---|---|---|
| Code-Gen | 92.3 | 92.1 | 91.8 |
| Bug-Fix | 88.4 | 88.6 | 88.9 |
| Refactoring | 87.9 | 87.5 | 87.1 |
| Instruction | 90.2 | 89.8 | 89.0 |
The results are mixed but mostly negative. No task type shows consistent improvement from step-back prompting. Code-gen and instruction tasks trend negative on both variants. Bug-fix shows marginal improvement, but it’s within noise.
Per-Task Highlights
Looking at individual tasks reveals the noise in this data:
- bug-fix-04: pitfalls helps (66.5 → 68.8, +2.3)
- instruction-01: pitfalls hurts (91.1 → 86.9, -4.2)
- code-gen-03: principles hurts (94.5 → 92.1, -2.4)
- refactor-02: both variants hurt (89.3 → 87.8 principles, 87.1 pitfalls)
There’s no coherent story here. Step-back prompting doesn’t unlock a specific capability or handle a particular task type better. It just adds variance.
Model-Specific Results
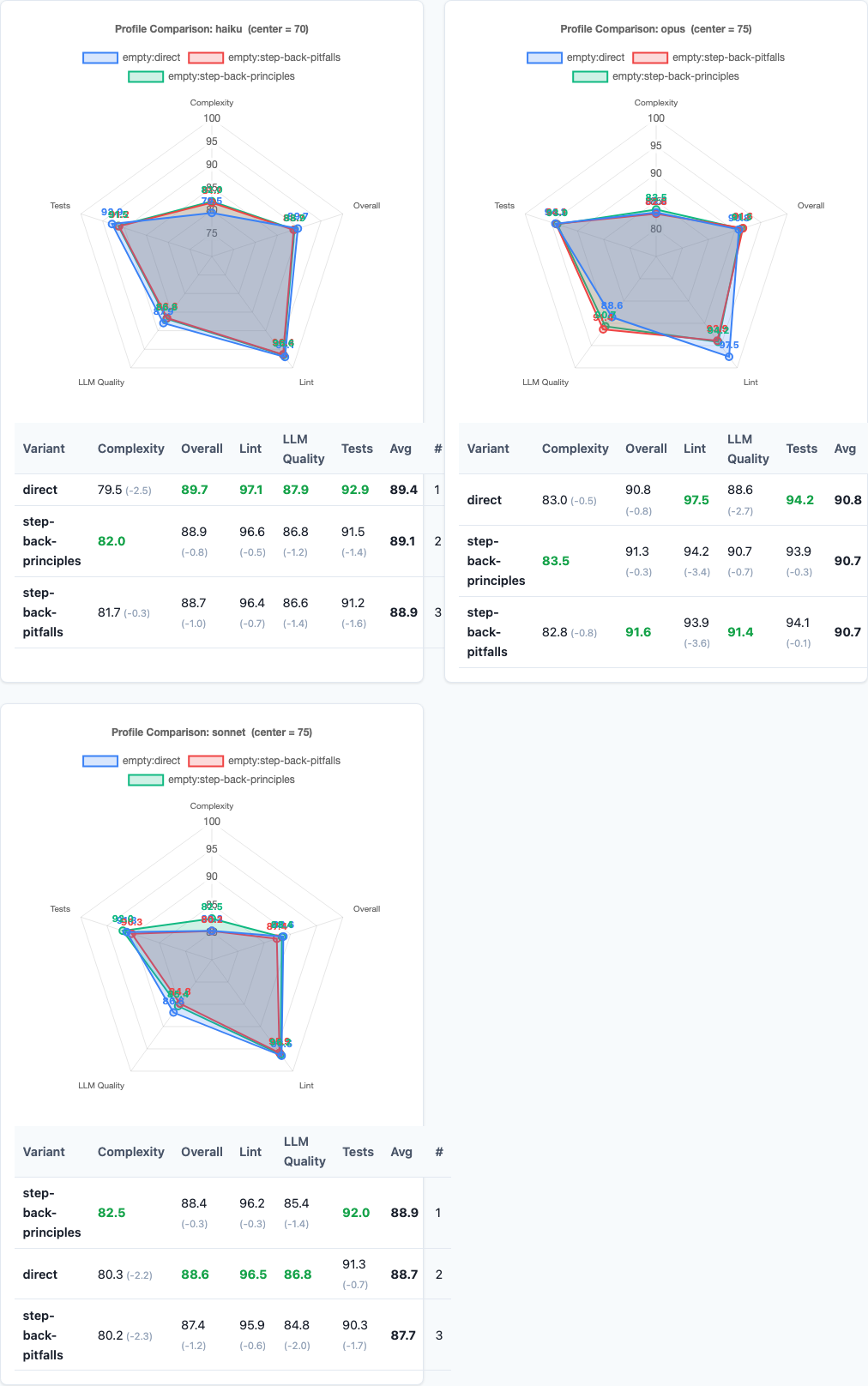
Radar charts: multi-dimensional performance comparison.
Do different models respond differently to step-back prompting?
| Model | Direct | Principles | Pitfalls |
|---|---|---|---|
| Haiku | 87.2 | 87.1 | 86.8 |
| Sonnet | 90.5 | 90.3 | 90.1 |
| Opus | 91.4 | 91.1 | 90.7 |
All three models trend slightly negative on both step-back variants. The pattern is consistent: step-back prompting doesn’t help, regardless of model capability. Haiku, Sonnet, and Opus all perform best with the direct control.
Variance and Consistency
Step-back prompting doesn’t just fail to improve scores—it also increases variance slightly:
| Variant | Stdev | CV (Coefficient of Variation) |
|---|---|---|
| direct/control | 12.4 | 13.8% |
| step-back-principles | 12.8 | 14.3% |
| step-back-pitfalls | 12.6 | 14.1% |
Both step-back variants have higher standard deviations and coefficients of variation than the direct control. The difference is small, but the direction is clear: adding meta-cognitive framing makes output less predictable, not more.
Connection to Chain-of-Thought
This finding directly validates what we discovered in the chain-of-thought experiment: asking AI to “think before acting” doesn’t improve code quality.
Why doesn’t this work for code when it works for physics and chemistry? Because coding isn’t reasoning about abstract principles—it’s executing a well-defined transformation. The model already knows the relevant principles. Asking it to articulate them first just burns tokens and introduces inconsistency between the stated principle and the implemented solution.
Practical Implications
1. Don’t use step-back prompting for code generation.
It doesn’t help. The direct control outperforms both variants with better consistency and lower token cost. Save your tokens for relevant context, not meta-cognitive framing.
2. Stop asking AI to “think about principles first.”
The model already has the principles internalized from training. Forcing it to articulate them adds latency, tokens, and variance without improving output. This is the same lesson as chain-of-thought: more thinking tokens ≠ better code.
3. Be skeptical of techniques that work for reasoning tasks.
Step-back prompting improved DeepMind’s physics and chemistry results. But code generation is not open-ended reasoning. Techniques that help with ambiguous, multi-step reasoning often hurt deterministic transformation tasks. Test everything on code before adopting it.
4. Token efficiency is quality.
This is another experiment confirming the r=-0.95 correlation between prompt tokens and code quality. Every token you add to the prompt is a token the model can’t use for output. Step-back prompting wastes 30-50 tokens per request for a -0.2 to -0.5 point penalty. Don’t do it.
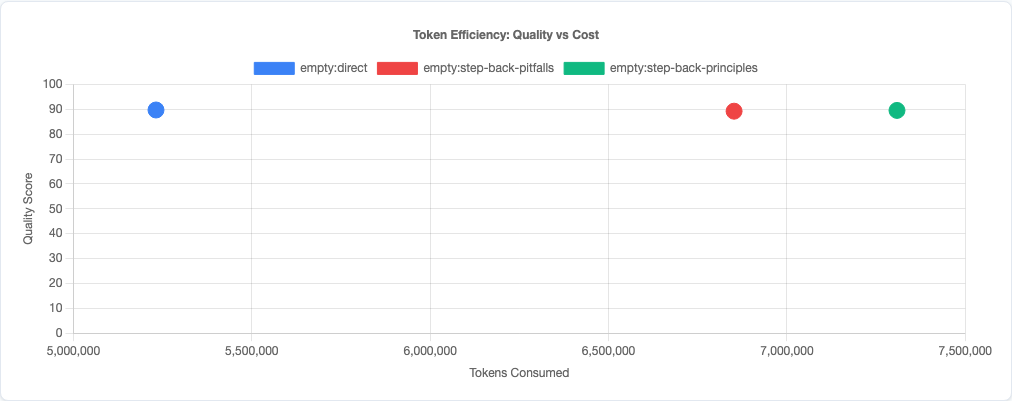
Token efficiency: quality vs cost tradeoff.
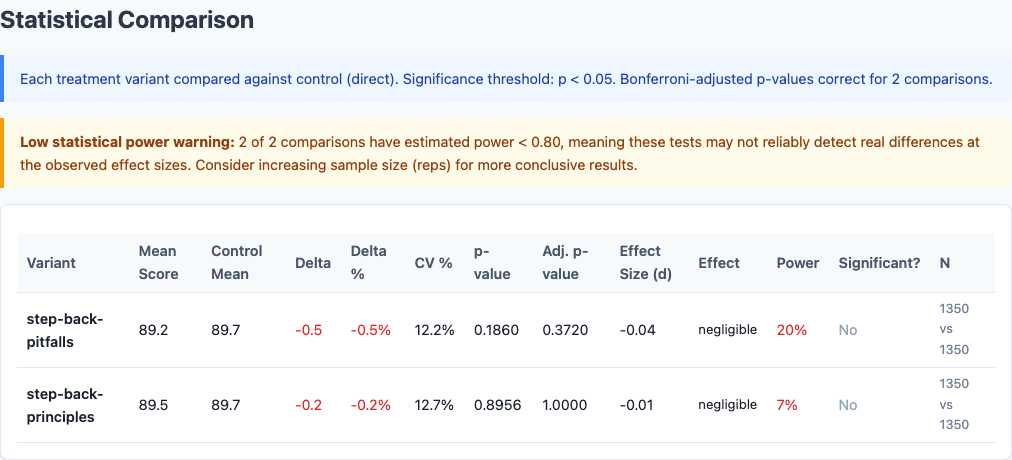
Statistical significance analysis.
Limitations
- Two step-back variants tested. We tested “identify principles” and “list pitfalls.” There may be other formulations of step-back prompting that work differently, though the pattern across both variants suggests the approach itself is the problem.
- Single-file tasks. These are isolated coding tasks. Step-back prompting might affect architectural decisions or multi-file refactoring differently than single-function implementations.
- Claude models only. Other model families (GPT-4, Gemini, etc.) may respond to step-back prompting differently. But given the consistent failure across Haiku, Sonnet, and Opus, I’m skeptical.
- No hybrid prompting tested. We didn’t test step-back combined with other strategies (like personas or politeness). Interaction effects could exist, though the base effect is clearly negative.
- Scoring rubric doesn’t reward principle articulation. Our rubric measures code correctness, not whether the model articulated principles. If your use case requires explanations, step-back prompting might still have value—just not for output quality.
Try It Yourself
The step-back experiment configuration and all data are open source:
pip install claude-benchmark
# Run the step-back experiment
claude-benchmark experiment run experiments/step-back.toml
# Generate the report
claude-benchmark report
# See the results
open results/*/report.htmlYou can also define your own step-back variants in the experiment TOML and test them against your specific task types. If you find a step-back formulation that actually helps code quality, I’d like to see the data.
Full experiment configuration: experiments/step-back.toml
For the complete picture of what works and what doesn’t in AI prompt engineering, see the capstone best-practices experiment where we combine the winning strategies from all experiments into a single optimized configuration.