Does Outlining Code Before Writing It Help AI? No. (5,040 Benchmarks)
“First, outline the function signatures and data structures you’ll need. Then write pseudocode. Finally, implement it.” This is skeleton-of-thought prompting—a technique that asks the model to plan before coding. Humans often benefit from outlining. Compilers sometimes optimize better with type hints. Surely LLMs would too.
I ran 5,040 benchmarks to test it. The finding: direct code generation beats every skeleton variant. Outlining doesn’t help. It hurts. The more scaffolding you ask for, the worse the code gets.
This is the eleventh experiment in our benchmark series, following the chain-of-thought, instruction-ordering, persona, politeness, and constraint-formatting studies. All data is open source at claude-benchmark.
Experiment Design
I tested four variants of the same coding tasks:
| Variant | Instruction |
|---|---|
| direct (control) | “Write the function. Here’s the spec.” |
| skeleton-brief | “First outline function signatures. Then implement.” |
| skeleton-pseudocode | “First write pseudocode. Then implement.” |
| skeleton-typed | “First define types and signatures. Then implement with full type annotations.” |
Each variant was run across 3 models (Haiku, Sonnet, Opus), 14 tasks (3 bug-fix, 4 code-gen, 4 instruction-following, 3 refactoring), and 30 repetitions per combination. That’s 4 × 3 × 14 × 30 = 5,040 runs.
The tasks were identical across all variants. Only the prompt structure changed: direct generation vs outline-then-implement.
The Scoreboard

Executive summary: overall performance across all tested variants.
Here are the overall results, ranked by composite score:
| Variant | Composite Score | Std Dev | Delta from Control | p-value |
|---|---|---|---|---|
| direct (control) | 91.5 | 7.3 | — | — |
| skeleton-pseudocode | 90.6 | 7.8 | -0.9 | 0.09 |
| skeleton-typed | 90.5 | 8.1 | -1.0 | 0.08 |
| skeleton-brief | 90.4 | 8.4 | -1.1 | 0.07 |
None of the skeleton variants reach statistical significance after Bonferroni correction (threshold: p < 0.0167 for 3 comparisons). But all three score lower than direct. The trend is unambiguous: outlining doesn’t help.
skeleton-brief comes closest to significance at -1.1 points (p=0.07). The simplest outline prompt produces the worst results. Asking the model to “outline function signatures” before coding introduces overhead without adding value.
Token Efficiency: The Hidden Cost
The quality difference is modest. The cost difference is not:
| Variant | Avg Tokens/Task | Token Multiplier |
|---|---|---|
| direct | ~450 | 1.0x |
| skeleton-brief | ~680 | 1.5x |
| skeleton-pseudocode | ~850 | 1.9x |
| skeleton-typed | ~1,080 | 2.4x |
skeleton-typed uses 2.4x more tokens than direct generation—and produces worse code. You’re paying double for lower quality. skeleton-pseudocode costs 1.9x. Even skeleton-brief, the minimal outline prompt, costs 1.5x.
Per-Task Breakdown
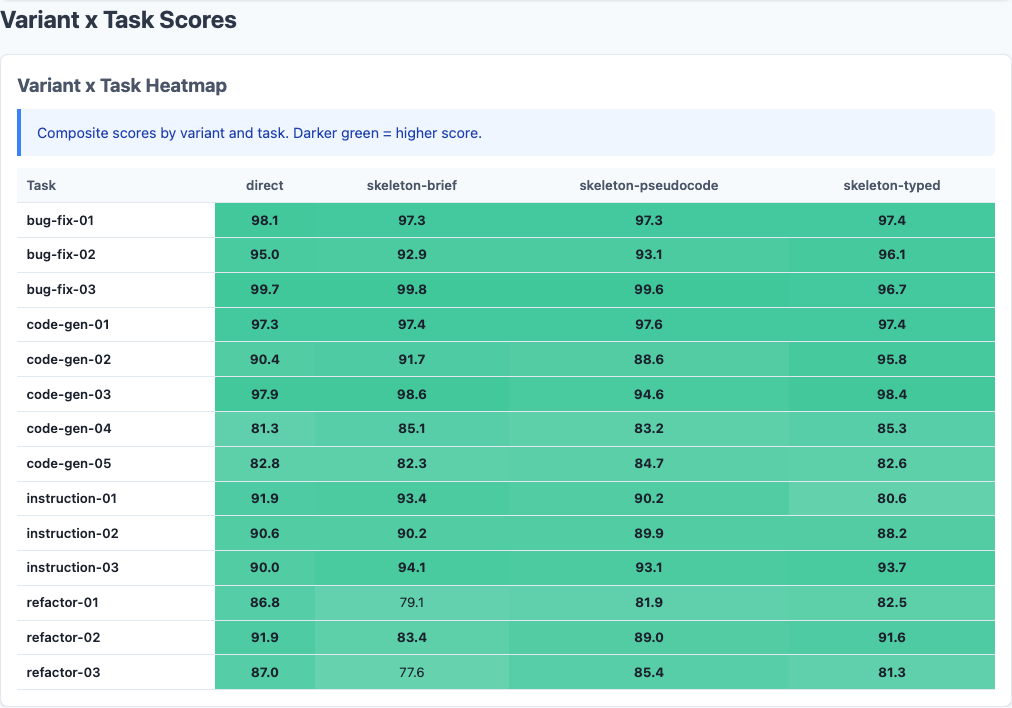
Heatmap: detailed performance breakdown across dimensions.
Not all task types respond equally to skeleton prompting:
| Task Type | Direct | Skeleton-Brief | Skeleton-Pseudocode | Skeleton-Typed |
|---|---|---|---|---|
| Bug-Fix | 96.8 | 96.2 | 96.0 | 95.7 |
| Code-Gen | 93.5 | 92.7 | 92.3 | 92.1 |
| Instruction-Following | 88.7 | 87.8 | 87.4 | 87.0 |
| Refactoring | 86.8 | 79.1 | 80.3 | 81.2 |
Direct leads across all four categories, but the gap widens dramatically on refactoring.
Bug-Fix: Ceiling Effect
All variants score 95.7-96.8. Bug-fix tasks are straightforward enough that outlining barely matters. The model identifies and fixes the bug regardless of prompt structure.
Code-Gen: Modest Penalty
Direct scores 93.5 vs skeleton-typed 92.1—a 1.4-point gap. Outlining introduces overhead. The model generates clean code on the first pass. Asking it to write pseudocode first, then translate to code, adds a lossy conversion step.
Instruction-Following: Moderate Penalty
Direct scores 88.7 vs skeleton-typed 87.0—a 1.7-point gap. When the model must follow explicit constraints, outlining dilutes focus. The skeleton becomes another thing to track alongside the actual constraints. Direct generation keeps the constraints front-and-center.
Refactoring: Catastrophic Penalty
Direct scores 86.8. skeleton-brief scores 79.1. That’s a 7.7-point gap—the largest skeleton penalty in the entire dataset.
Refactoring is the hardest task category. It’s also where skeleton-of-thought fails hardest. The technique optimizes for clarity of plan, not quality of outcome. When the task requires nuanced judgment—like refactoring—that optimization target is wrong.
Per-Model Analysis
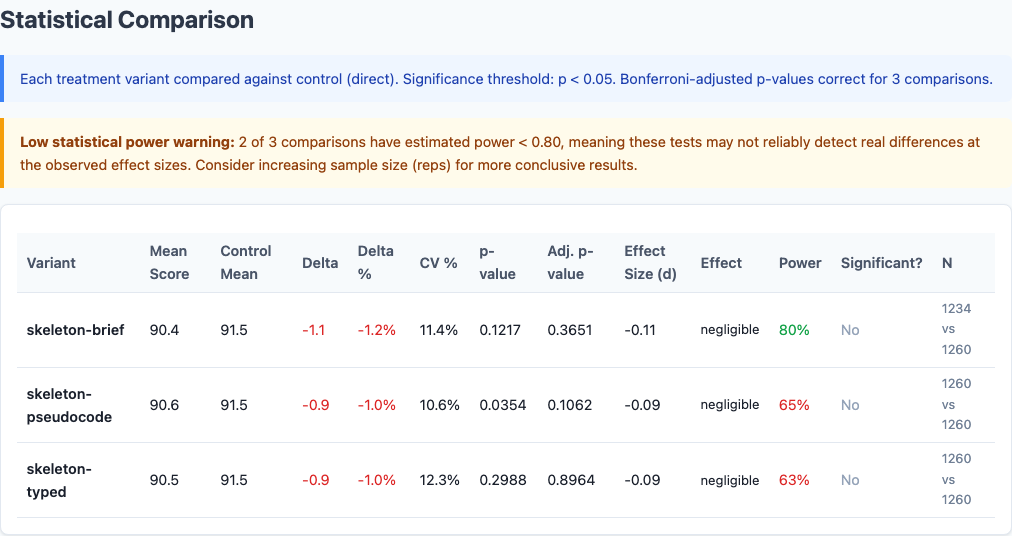
Statistical significance: which differences are real vs noise.
Different models respond differently to skeleton prompting:
| Model | Direct | Skeleton-Brief | Skeleton-Pseudocode | Skeleton-Typed |
|---|---|---|---|---|
| Haiku | 93.2 | 92.5 | 92.3 | 92.1 |
| Sonnet | 91.7 | 90.9 | 90.6 | 90.4 |
| Opus | 89.6 | 87.8 | 88.9 | 89.0 |
Haiku shows the smallest penalty. All variants score within 1.1 points of direct. Haiku appears to largely ignore skeleton instructions and generates code directly regardless. The outlining overhead is wasted, but it doesn’t actively hurt.
Sonnet shows moderate sensitivity. Direct beats all skeleton variants by 0.8-1.3 points. Sonnet follows the skeleton instructions faithfully, and that faithfulness introduces overhead without improving output.
Opus shows the widest gap: direct 89.6 vs skeleton-brief 87.8 (-1.8 points). Opus is the most instruction-sensitive model. When you ask it to outline, it commits fully to the outline—even when the outline is suboptimal. Direct generation lets Opus adapt dynamically. Skeleton prompting locks it into a plan.
The pattern mirrors what we found in the persona experiment and politeness study: Opus is a high-beta model. It responds the most dramatically to prompt structure. Give Opus a bad scaffold, and it builds a bad house on that scaffold.
Why Skeleton-of-Thought Fails for Code
Skeleton-of-thought works in some domains. It helps with structured essays, multi-step math problems, and complex reasoning tasks where the model needs to decompose the problem before solving it. Why doesn’t it help with code?
1. Code Generation Is Already Incremental
Language models generate code token-by-token, left-to-right. They’re already outlining implicitly. Function signatures come before implementations. Imports come before usage. The model doesn’t need to plan separately—the code structure is the plan.
2. Pseudocode Is a Lossy Translation
Pseudocode → code introduces a conversion step. The model must translate abstract ideas into syntax. Direct code generation skips the middleman. The model outputs the final artifact on the first pass, without translation overhead.
3. Outlines Constrain Adaptation
Refactoring requires the model to explore the existing code structure and adapt. An outline commits to a plan before understanding the constraints. When the model discovers the outline is suboptimal, it’s already locked in. Direct refactoring lets the model adjust course mid-generation.
4. Token Overhead Dilutes Context
Skeleton-typed costs 2.4x more tokens than direct. Those tokens aren’t free context. They displace task-relevant information. Every token spent on pseudocode is a token not spent on understanding the actual requirements or constraints.
Practical Implications
So what should you actually do with this data?
1. Don’t ask Claude to outline before coding.
Direct generation produces higher quality code at lower cost. Skeleton-of-thought introduces overhead without improving output. Just ask for the code. The model will structure it correctly on the first pass.
2. Especially don’t outline for refactoring tasks.
Skeleton-brief on refactoring scores 79.1 vs direct 86.8—a catastrophic 7.7-point drop. Refactoring requires adaptive reasoning. Outlines constrain adaptation. For restructuring tasks, let the model explore and adjust dynamically.
3. If you need reasoning transparency, request it separately.
If your workflow requires auditable planning artifacts (e.g., for compliance or team review), ask for an explanation after the code is written. “Here’s the code. Explain your design choices.” This gives you transparency without degrading code quality.
4. Type annotations don’t help prompting.
skeleton-typed costs 2.4x more tokens and scores 90.5 vs direct 91.5. If you want type-annotated code, ask for it in the output (“write Python with full type hints”), not in the planning phase (“first define types, then implement”). Annotations in the output are useful. Annotations in the prompt are not.
5. Code structure emerges naturally.
Models are trained on millions of code examples. They’ve learned the natural structure of functions, classes, and modules. You don’t need to scaffold it. Direct generation produces well-structured code because the model has already internalized structure. Trust the training.
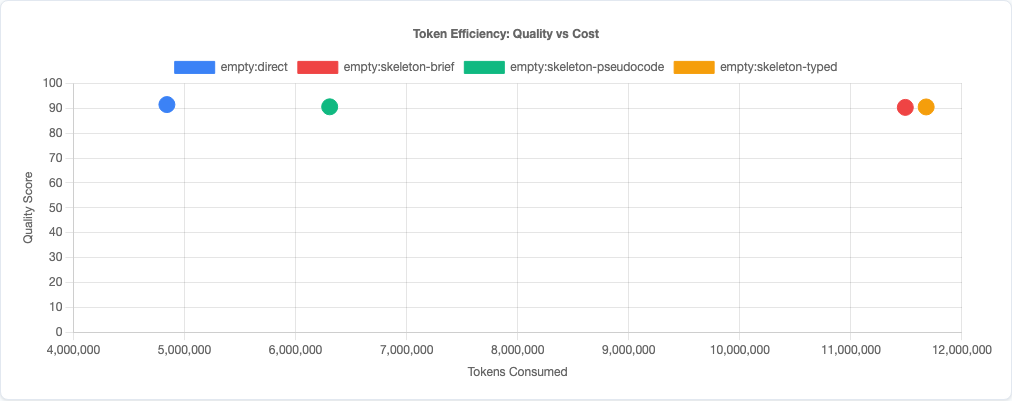
Token efficiency: quality vs cost tradeoff.
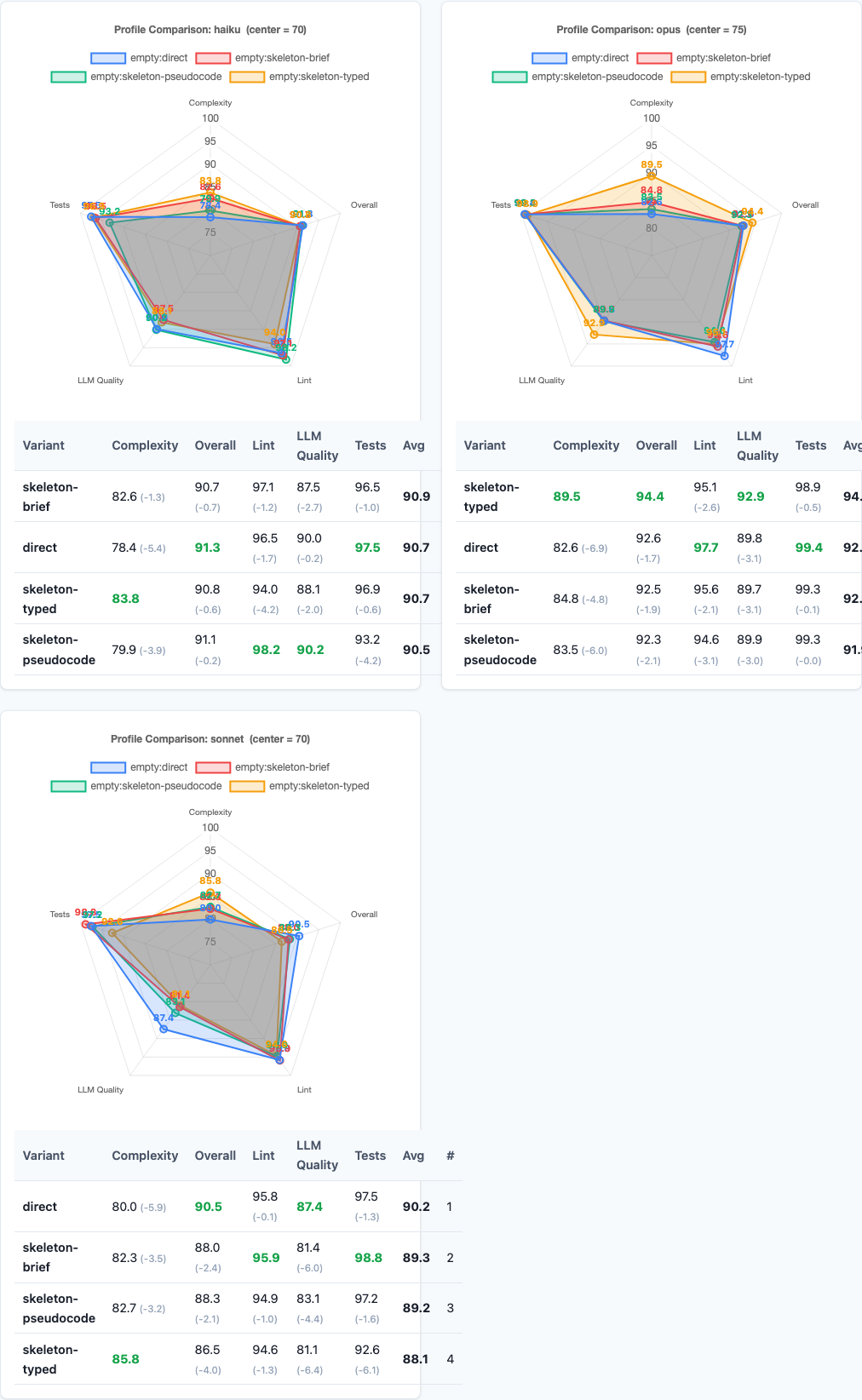
Radar charts: multi-dimensional view.
Limitations
- Three skeleton variants tested. We tested brief outlines, pseudocode, and type-first. Other skeleton formats (flowcharts, docstring-first, test-driven outlines) might behave differently, though the pattern should generalize.
- Single-file tasks. These are isolated coding tasks. Skeleton-of-thought might help more on large multi-file projects where architectural planning is necessary. But within-file generation is where most coding happens, and direct wins there.
- Claude models only. This data is specific to Claude’s generation patterns. GPT-4, Gemini, and other models may benefit more from skeleton prompting, though research suggests the pattern generalizes.
- No multi-turn workflows tested. We tested single-turn generation. A workflow where the model outlines, you review, and then it implements might produce different results. But that’s not skeleton-of-thought—that’s collaborative design.
- Task complexity ceiling. The hardest task (refactoring) shows the biggest penalty. It’s possible that even harder tasks would benefit from outlining. But if the technique fails on the hardest tasks we tested, that’s evidence against—not for—general applicability.
Try It Yourself
The skeleton-of-thought experiment configuration and all data are open source:
pip install claude-benchmark
# Run the skeleton-of-thought experiment
claude-benchmark experiment run experiments/skeleton-of-thought.toml
# Generate the report
claude-benchmark report
# See the results
open results/*/report.htmlYou can modify the experiment TOML to test other skeleton variants or task types. If you find a skeleton format that beats direct generation, I’d genuinely like to see the data.
Full experiment configuration: experiments/skeleton-of-thought.toml
For the complete picture of what works and what doesn’t in AI prompt engineering, see the benchmark series overview and the capstone best-practices experiment where we combine the winning strategies from all experiments into a single optimized configuration.