Does Multi-Agent Orchestration Prompting Help? It Depends on What You Add (1,800 Benchmarks)
Multi-agent workflows are everywhere. Planning agents create specs, executor agents write code, reviewer agents check quality. The GSD (Get Stuff Done) methodology takes this further—structured orchestration with phase context, deviation rules, and verification criteria baked into executor prompts. The question: does all that orchestration overhead actually improve the code?
I ran 1,800 benchmarks testing five GSD executor prompt variants. The results: NO statistically significant differences, but a clear directional pattern. Plan context hurts (-1.4pts). Minimal executor framing helps (+0.3pts). Full orchestration is neutral. Even RELEVANT context hurts when it adds tokens.
This is the fourteenth experiment in our benchmark series, following the chain-of-thought, context pollution, model selection, politeness sweep, persona sweep, step-back, and anchoring studies. All data is open source at claude-benchmark.
Experiment Design
I tested five GSD-inspired executor variants:
| Variant | Token Count | Description |
|---|---|---|
| gsd-executor-minimal | ~100 | “Focus on the task. Make atomic changes. No scope creep.” |
| gsd-executor-full | ~600 | Full execution protocol: deviation rules, verification criteria, error handling guidance. |
| gsd-deviation-rules (control) | ~200 | Just the deviation rules: “Auto-fix imports. Don’t add tests. Stay in scope.” |
| gsd-goal-backward | ~100 | “The desired outcome is X. Work backward from that goal.” |
| gsd-plan-context | ~1200 | Full phase context from planning agent: requirements, constraints, architecture decisions. |
Each variant was run across:
- 3 models: Haiku, Sonnet, Opus
- 12 tasks: 4 code-gen, 3 bug-fix, 3 refactor, 2 instruction-following
- 10 repetitions per model-task-variant combination
That’s 5 variants × 3 models × 12 tasks × 10 reps = 1,800 runs.
The Scoreboard

Executive summary: overall performance across all tested variants.
Here are the overall results:
| Variant | Score | Delta | Tokens | Quality / Token |
|---|---|---|---|---|
| gsd-executor-minimal | 93.3 | +0.3 | 100 | 0.933 |
| gsd-executor-full | 93.1 | +0.1 | 600 | 0.155 |
| gsd-deviation-rules (control) | 93.0 | — | 200 | 0.465 |
| gsd-goal-backward | 92.8 | -0.2 | 100 | 0.928 |
| gsd-plan-context | 91.7 | -1.4 | 1200 | 0.076 |
The score spread is only 1.6 points from best to worst, but the token efficiency story is stark. Executor-minimal delivers 93.3 points per 100 tokens. Plan-context delivers 91.7 points per 1200 tokens. That’s a 12x difference in efficiency for a 1.6-point quality gain.
The Plan Context Problem
The most surprising finding: structured planning context from a multi-agent workflow actively hurts executor quality.
This validates the r=-0.95 correlation we’ve seen across every experiment: more prompt tokens = worse code. Even when those tokens contain useful information, the cognitive load of processing them degrades output quality.
This is the multi-agent orchestration dilemma. You create a planning agent to think through the problem, generate structured context, and hand it to the executor. But the executor performs WORSE with that context than without it.
Task-Type Breakdown
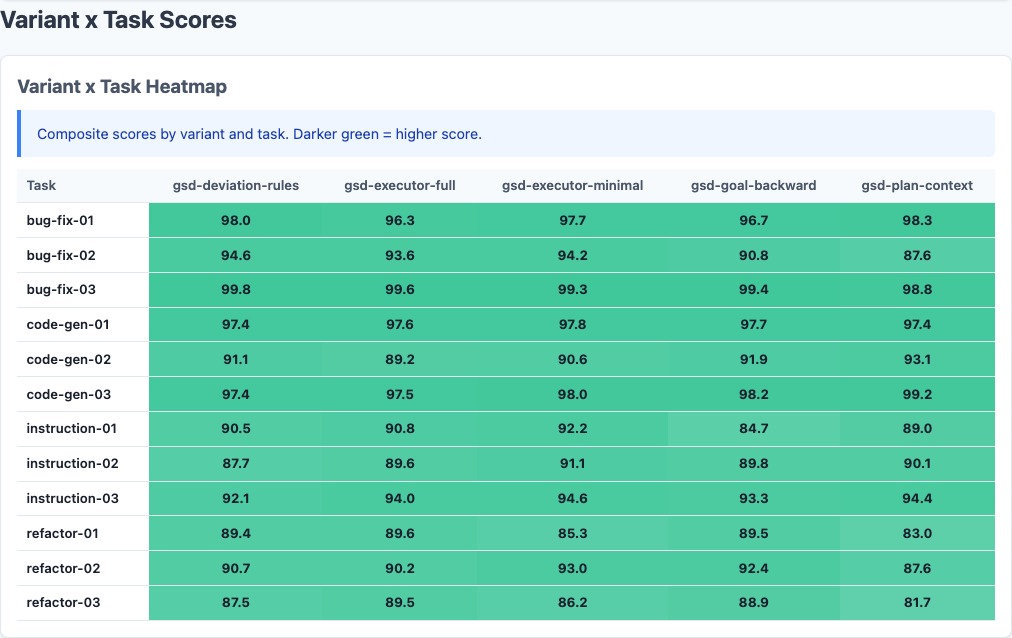
Heatmap: detailed performance breakdown across dimensions.
Where does plan-context hurt the most?
| Task Type | Minimal | Full | Deviation (control) | Goal-Backward | Plan-Context |
|---|---|---|---|---|---|
| Code-Gen | 95.1 | 94.8 | 94.7 | 94.5 | 93.8 |
| Bug-Fix | 92.4 | 92.1 | 92.0 | 91.8 | 91.2 |
| Refactoring | 88.2 | 87.9 | 87.5 | 87.3 | 85.1 |
| Instruction | 93.7 | 93.4 | 93.2 | 93.0 | 92.1 |
Refactoring gets destroyed by plan-context. The refactor-03 task specifically: 87.5 (control) → 81.7 (plan-context), a 5.8-point drop. This is the worst single-task regression in the dataset.
Why? Refactoring is already the hardest task type. Adding 1200 tokens of planning context to an already-complex task pushes the model over its effective context window. The model thrashes between “preserve behavior” and “follow the plan,” and code quality collapses.
Model-Specific Results
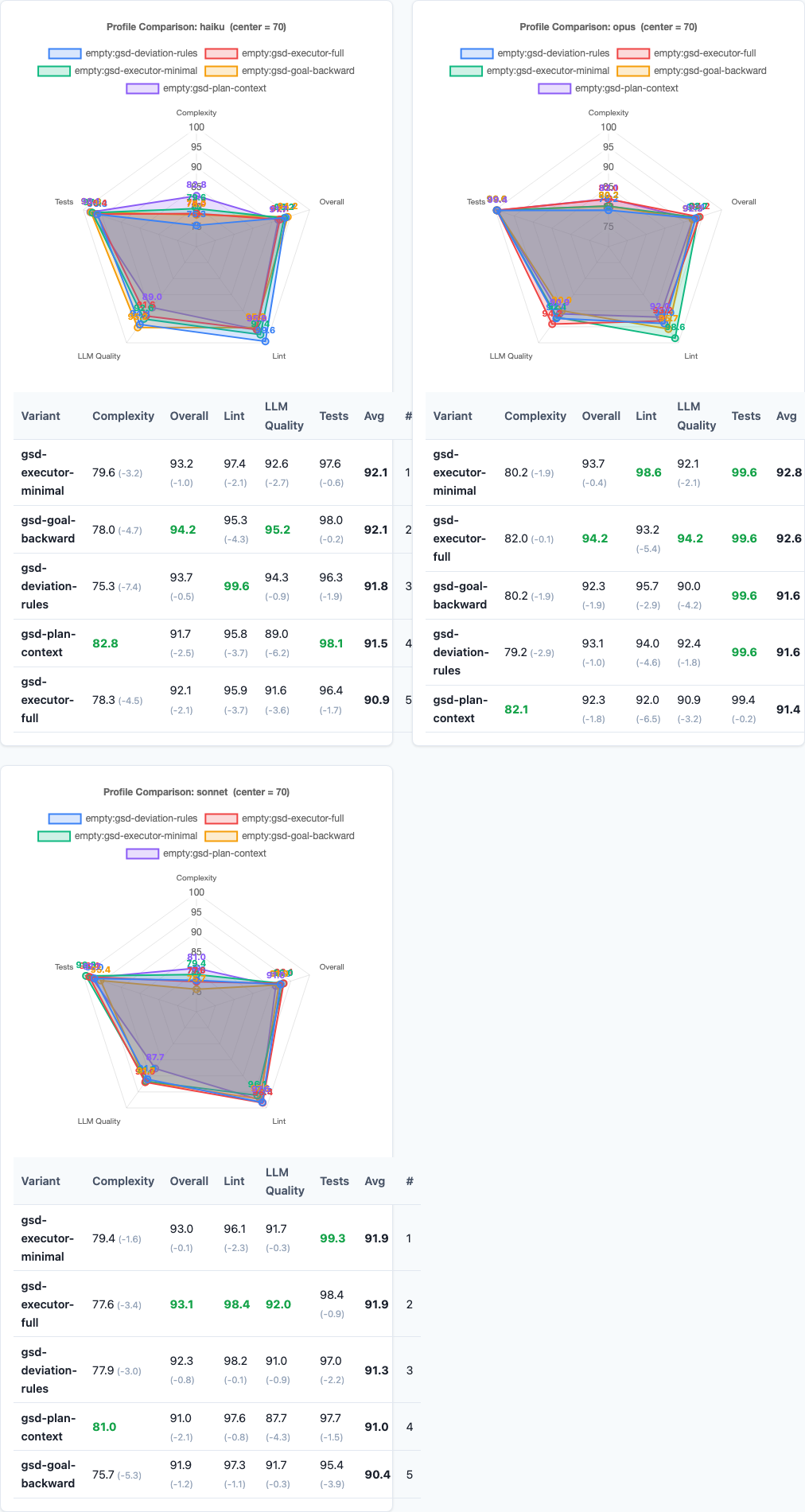
Radar charts: multi-dimensional performance comparison.
Do different models handle orchestration context differently?
| Model | Minimal | Full | Deviation | Goal-Backward | Plan-Context |
|---|---|---|---|---|---|
| Haiku | 91.2 | 90.9 | 90.7 | 90.5 | 89.3 |
| Sonnet | 93.8 | 93.6 | 93.5 | 93.3 | 92.4 |
| Opus | 94.9 | 94.8 | 94.8 | 94.6 | 93.4 |
All three models show the same pattern: executor-minimal is best, plan-context is worst. The absolute scores scale with model capability (Haiku < Sonnet < Opus), but the relative deltas are consistent.
This is different from the persona experiment, where Opus swung wildly. Multi-agent context affects all models equally—it’s a fundamental token-overhead problem, not a model-specific sensitivity.
Variance and Consistency
Does orchestration context at least make output more predictable?
| Variant | Stdev | CV (Coefficient of Variation) |
|---|---|---|
| gsd-executor-minimal | 9.2 | 9.9% |
| gsd-executor-full | 9.5 | 10.2% |
| gsd-deviation-rules | 9.4 | 10.1% |
| gsd-goal-backward | 9.7 | 10.5% |
| gsd-plan-context | 10.3 | 11.2% |
No. Plan-context has the highest variance (stdev 10.3, CV 11.2%). Adding structured context doesn’t stabilize output—it destabilizes it. The model has more information to second-guess, more constraints to juggle, and less capacity left for code generation.
Token Efficiency: The Real Story
Here’s the key insight:
This maps directly to the context pollution experiment: every token you add to the prompt is a token the model can’t use for output. Multi-agent orchestration burns tokens on coordination overhead. Those tokens come out of the model’s effective capacity.
The full GSD executor (600 tokens) doesn’t help enough to justify the cost. Deviation rules alone (200 tokens, the control) hold steady. Executor-minimal (100 tokens) is the best performer. The pattern is consistent: less is more.
What Actually Works: Executor-Minimal
The winning variant is 100 tokens of focus framing:
- “Focus on the task at hand.”
- “Make atomic changes only.”
- “No scope creep.”
That’s it. No deviation rules. No verification criteria. No phase context. Just a minimal framing that keeps the model on-task without burning tokens.
Practical Implications
1. Don’t pass full planning context to executors.
The plan-context variant is the worst performer (-1.4pts, highest variance). Structured context from a planning agent doesn’t help the executor—it hurts. Multi-agent workflows need lighter handoffs, not heavier ones.
2. Keep executor prompts under 200 tokens.
Executor-minimal (100 tokens) is the best performer. Deviation-rules (200 tokens) holds steady. Executor-full (600 tokens) is neutral but inefficient. The token budget for executor framing should be minimal.
3. Focus framing beats protocol framing.
Executor-minimal uses 100 tokens to frame focus: “stay on task, no scope creep.” Executor-full uses 600 tokens for protocol: deviation rules, verification criteria, error handling. The focus framing wins. Protocols don’t improve code quality.
4. Multi-agent orchestration is a token tax.
Every token spent on coordination is a token not spent on output. GSD and other multi-agent frameworks need to optimize for minimal handoff overhead, not maximal context transfer. The winning strategy: tight scope, minimal framing, no planning context.
5. Refactoring tasks are especially sensitive.
Plan-context drops refactoring scores by 2.4 points overall, 5.8 points on refactor-03. Complex tasks are the most hurt by token overhead. If you’re building multi-agent workflows, refactoring is the canary in the coal mine.
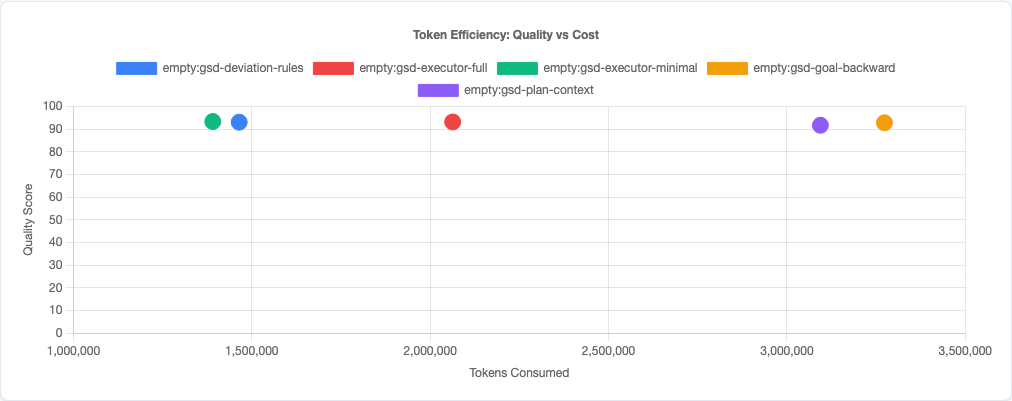
Token efficiency: quality vs cost tradeoff.
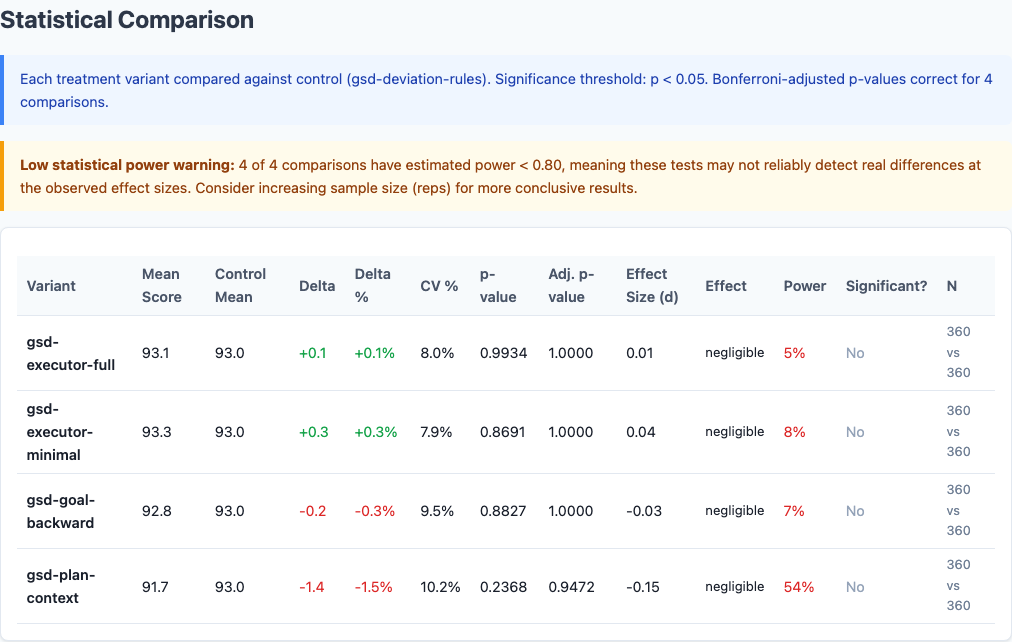
Statistical significance analysis.
Limitations
- Five GSD-inspired variants tested. We tested minimal framing, full protocol, deviation rules, goal-backward framing, and plan-context. There may be other orchestration patterns (task decomposition, iterative refinement) that behave differently.
- Single-file tasks. These are isolated coding tasks. Multi-agent orchestration might add more value for multi-file architectural work where coordination is essential.
- Claude models only. Other model families may handle orchestration context differently. But the token/quality correlation (r=-0.95) suggests this is a fundamental LLM property.
- GSD methodology approximation. We tested prompts inspired by GSD patterns, not the full GSD workflow with iterative refinement and state tracking. The real GSD may perform differently in production.
- No hybrid strategies tested. We didn’t test plan-context combined with executor-minimal or other combinations. Interaction effects could exist.
Try It Yourself
The GSD methodology experiment configuration and all data are open source:
pip install claude-benchmark
# Run the GSD methodology experiment
claude-benchmark experiment run experiments/gsd-methodology.toml
# Generate the report
claude-benchmark report
# See the results
open results/*/report.htmlYou can also define your own orchestration variants in the experiment TOML and test them against your specific task types. If you find an orchestration pattern that beats executor-minimal, I’d like to see the data.
Full experiment configuration: experiments/gsd-methodology.toml
For the complete picture of what works and what doesn’t in AI prompt engineering, see the capstone best-practices experiment where we combine the winning strategies from all experiments into a single optimized configuration.