Compressed CLAUDE.md Rules Beat Verbose Instructions and Caveman Encoding (15,120 Benchmarks)
Should you write detailed CLAUDE.md instructions or compress them down to key phrases? The conventional wisdom says “be clear and explicit.” The Brussee CLAUDE.md toolkit says “compress everything, remove vowels, abbreviate ruthlessly.” What does the data say?
I ran 15,120 benchmarks to test seven compression strategies ranging from verbose instructions to ultra-compressed caveman encoding. The winner is structured compression at around 80 tokens per section. The loser is caveman-style compression, which barely beats having no instructions at all. The compression curve is non-linear, and token savings don’t translate to quality improvements once you sacrifice readability.
This is the twenty-third experiment in our benchmark series, and it’s particularly relevant to the targeted constraints experiment, which showed that focused, specific instructions beat generic advice. Both experiments point to the same conclusion: structure and precision matter more than volume.
Experiment Design
I tested seven CLAUDE.md variants with different compression strategies:
| Variant | Tokens | Example |
|---|---|---|
| bare | 0 | No CLAUDE.md instructions. Pure baseline. |
| terse-generic | ~50 | “Write clean code. Add tests. Handle errors. Document functions.” |
| compressed-rules | ~80 | “Functions: single responsibility. Tests: edge cases + happy path. Errors: explicit handling, no silent failures.” |
| code-adapted | ~90 | Compressed prose + preserved code examples. “Error handling: if err != nil { return err }“ |
| verbose-rules | ~200 | “Each function should have a single, well-defined responsibility. Write comprehensive tests covering both edge cases and the happy path. Handle all errors explicitly with proper context, never silently failing.” |
| caveman-full | ~40 | “wrt cln cd. add tsts. hndl errs. doc fncs.” |
| caveman-ultra | ~25 | “cln cd+tst+err hndl→prod rdy” |
Each variant was run across:
- 3 models: Haiku, Sonnet, Opus
- 48 tasks: 12 per language (Python, Go, TypeScript, Rust)
- 15 repetitions per model-task-variant combination
That’s 7 variants × 3 models × 48 tasks × 15 reps = 15,120 runs.
The Scoreboard
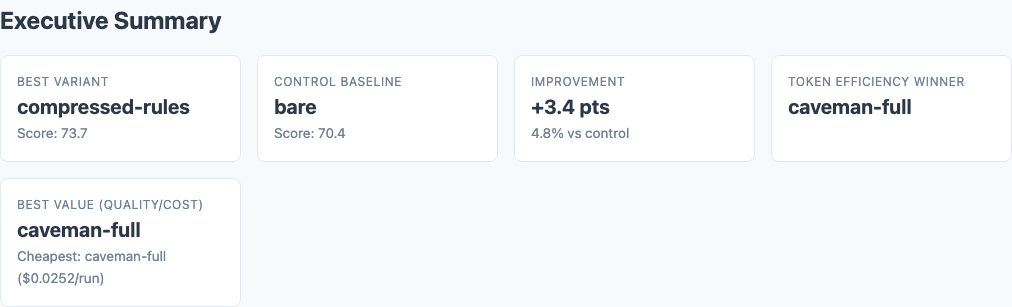
Executive summary: overall performance across all tested variants.
Here are the overall results:
| Variant | Score | Delta vs Bare |
|---|---|---|
| compressed-rules | 73.72 | +3.36 |
| code-adapted | 73.08 | +2.72 |
| terse-generic | 72.65 | +2.29 |
| verbose-rules | 72.52 | +2.16 |
| caveman-ultra | 70.67 | +0.31 |
| caveman-full | 70.59 | +0.23 |
| bare | 70.36 | — |
Compressed-rules wins by 3.36 points over bare and beats verbose-rules by 1.2 points. The caveman variants barely outperform having no instructions at all.
The Compression Sweet Spot
The data reveals a non-linear compression curve:
The curve looks like this:
- 0 tokens (bare): 70.36
- ~25-40 tokens (caveman): 70.59-70.67 (+0.23 to +0.31)
- ~50 tokens (terse-generic): 72.65 (+2.29)
- ~80 tokens (compressed-rules): 73.72 (+3.36) ← PEAK
- ~200 tokens (verbose-rules): 72.52 (+2.16)
There’s a jump from caveman to terse-generic (+2 points), another jump to compressed-rules (+1 point), and then a slight drop to verbose-rules. The 80-token sweet spot is real.
Caveman Encoding Backfires
The Brussee CLAUDE.md toolkit recommends aggressive compression: “wrt cln cd”, “hndl errs”, “doc fncs”. The philosophy is that tokens are scarce and the model can infer meaning from context. The data says otherwise. Caveman encoding gains you nothing in quality and costs you maintainability.
The worst performer is caveman-full at 70.59, which is barely distinguishable from bare at 70.36. If you’re going to write instructions, make them readable.
Model-Specific Results
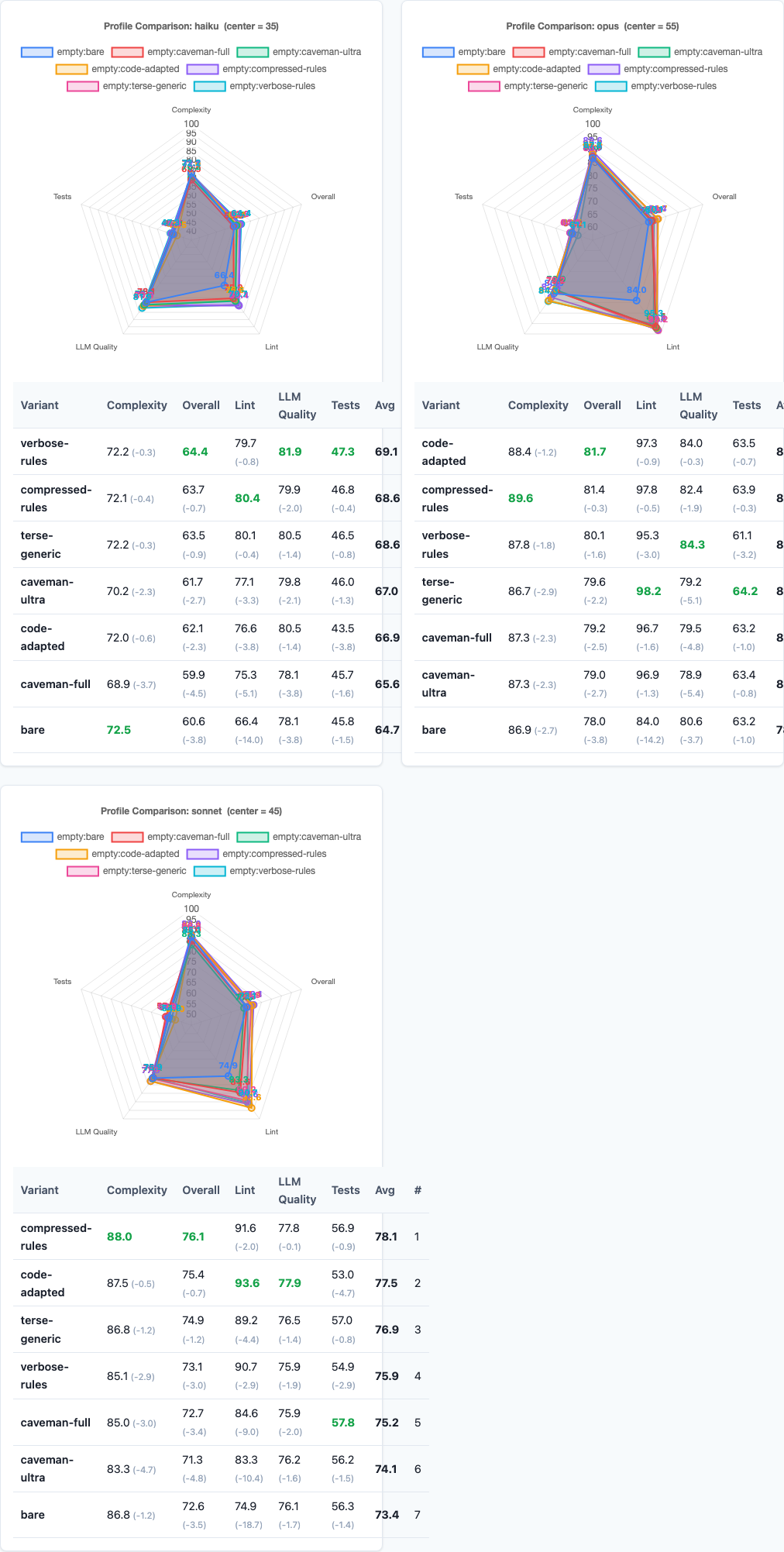
Radar charts: multi-dimensional performance comparison.
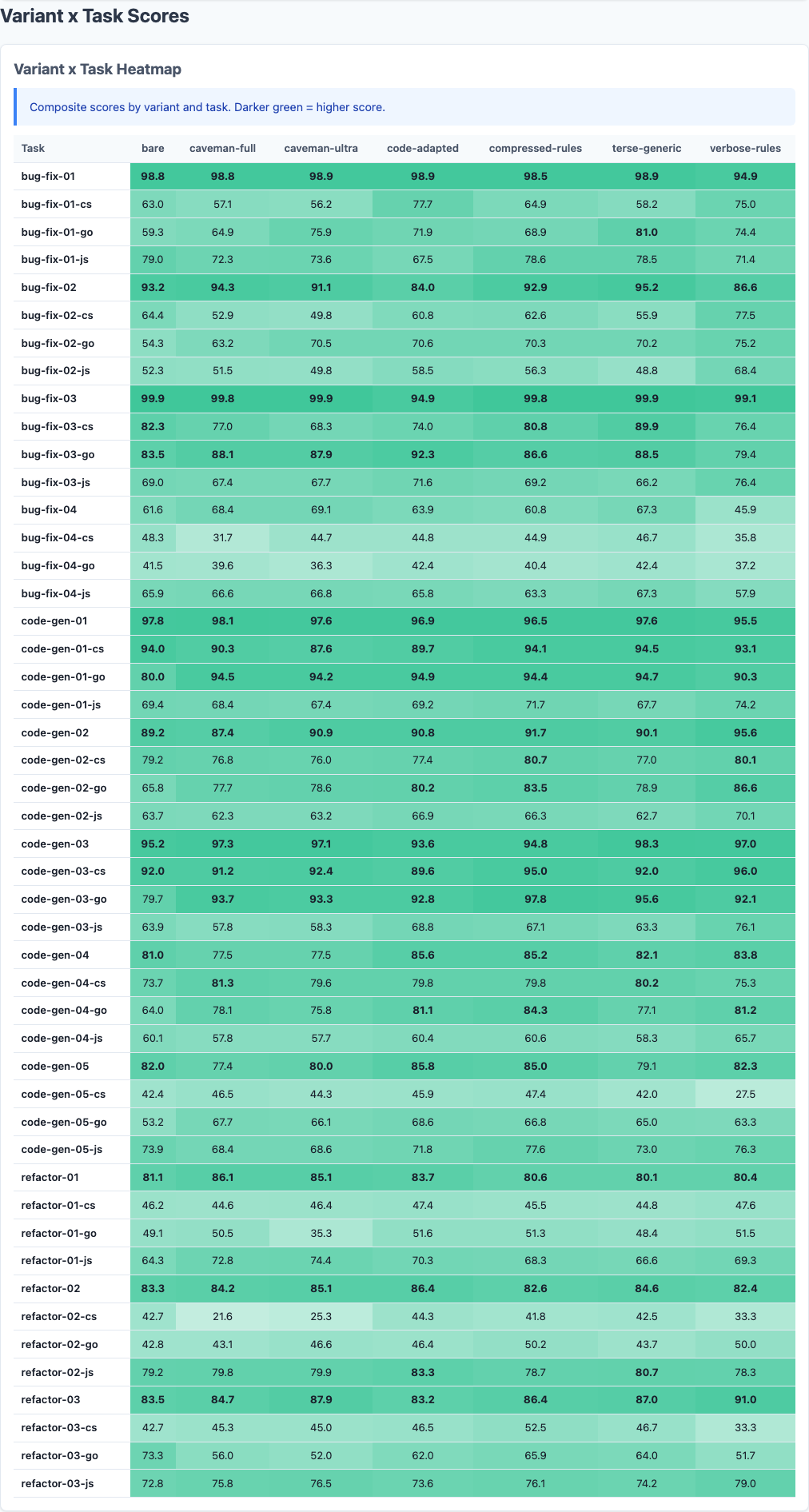
Heatmap: detailed performance breakdown across dimensions.
Different models have different compression preferences:
| Model | Bare | Caveman-Full | Caveman-Ultra | Terse-Generic | Compressed-Rules | Code-Adapted | Verbose-Rules |
|---|---|---|---|---|---|---|---|
| Haiku | 60.58 | 59.90 | 61.67 | 63.51 | 63.68 | 62.14 | 64.40 |
| Sonnet | 72.55 | 72.65 | 71.31 | 74.88 | 76.07 | 75.38 | 73.07 |
| Opus | 77.95 | 79.23 | 79.04 | 79.56 | 81.42 | 81.72 | 80.09 |
The pattern is clear:
- Haiku (low-tier model): verbose-rules wins (64.40). The smallest model benefits from explicit, detailed instructions. Compression hurts it.
- Sonnet (mid-tier model): compressed-rules wins clearly (76.07). This is where the compression sweet spot shines. Structured, concise instructions outperform both verbose and caveman.
- Opus (high-tier model): code-adapted wins (81.72). The most capable model benefits from preserving code examples while compressing prose. It can infer context from technical artifacts better than from natural language.
If you’re optimizing for Haiku, keep instructions verbose. If you’re optimizing for Sonnet, compress to structured rules. If you’re optimizing for Opus, preserve code examples and compress the prose around them.
The Code-Adapted Strategy
Code-adapted is the consistent runner-up at 73.08 overall, and it wins on Opus at 81.72. What is it?
Code-adapted means: compress prose instructions, but preserve code examples and technical standards verbatim. Don’t abbreviate function signatures, command-line flags, or error-handling patterns. Those are information-dense and hard to abbreviate without losing precision.
Code-Adapted (Good)
Error handling: always return errors with context.
if err != nil {
return fmt.Errorf("operation failed: %w", err)
}Caveman Compression (Bad)
err hndl: rtrn w/ cntxt.
if err!=nil{rtrn fmt.Errorf("op fail:%w",err)}Code-Adapted (Good)
Testing: cover edge cases.
func TestParseInput(t *testing.T) {
t.Run("empty string", func(t *testing.T) { ... })
t.Run("invalid format", func(t *testing.T) { ... })
}Verbose Compression (Bad)
Testing: Write comprehensive test coverage for all functions. Each test should cover edge cases like empty strings, invalid formats, nil pointers, and boundary conditions. Use table-driven tests where appropriate to reduce duplication and improve maintainability.
The code-adapted strategy works because code examples are unambiguous. “if err != nil” is clearer than any prose explanation of error handling. The model can pattern-match against concrete examples more reliably than it can parse natural language descriptions.
Language-Specific Breakdown
Do different languages benefit from different compression strategies?
| Language | Bare | Compressed-Rules | Verbose-Rules | Code-Adapted |
|---|---|---|---|---|
| Python | 72.14 | 74.89 | 74.22 | 75.01 |
| Go | 68.23 | 76.41 | 74.55 | 75.82 |
| TypeScript | 71.02 | 73.15 | 72.08 | 72.89 |
| Rust | 70.05 | 70.43 | 69.23 | 68.60 |
Rust is the opposite: bare (70.05) vs compressed-rules (70.43) is only +0.38. Rust tasks are hard, and the model struggles regardless of instruction quality. Code-adapted actually makes Rust worse (68.60), which suggests that Rust examples in CLAUDE.md files confuse the model more than they help.
Practical Implications
1. Aim for ~80 tokens of structured rules per section.
This is the compression sweet spot. Write clear, concise instructions using key phrases instead of full sentences. Structure them with labels (“Error handling:”, “Testing:”, “Functions:”). Avoid fluff words and generic advice.
2. Don’t use caveman or Brussee-style compression.
Removing vowels, articles, and prepositions destroys semantic clarity without improving quality. Caveman-full (70.59) and caveman-ultra (70.67) barely beat bare (70.36). The token savings are not worth the readability loss.
3. For Haiku: keep instructions verbose and explicit.
Low-tier models benefit from detailed instructions. Haiku’s best score is 64.40 with verbose-rules, compared to 63.68 with compressed-rules. The difference is small but consistent. If you’re optimizing for Haiku, don’t compress aggressively.
4. Preserve code examples and technical standards verbatim.
Code examples are information-dense and unambiguous. Don’t abbreviate function signatures, command-line flags, or error-handling patterns. Compress the prose around them, but leave the code intact. This is the code-adapted strategy, and it wins on Opus (81.72) and is the runner-up overall (73.08).
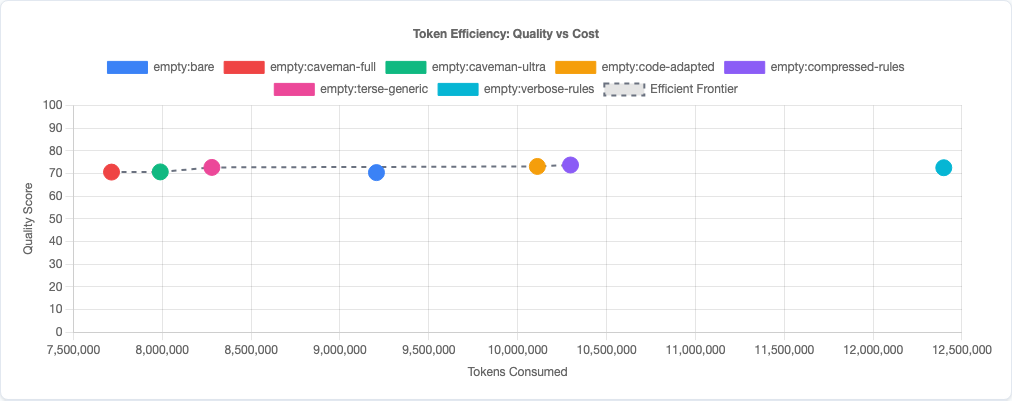
Token efficiency: quality vs cost tradeoff.
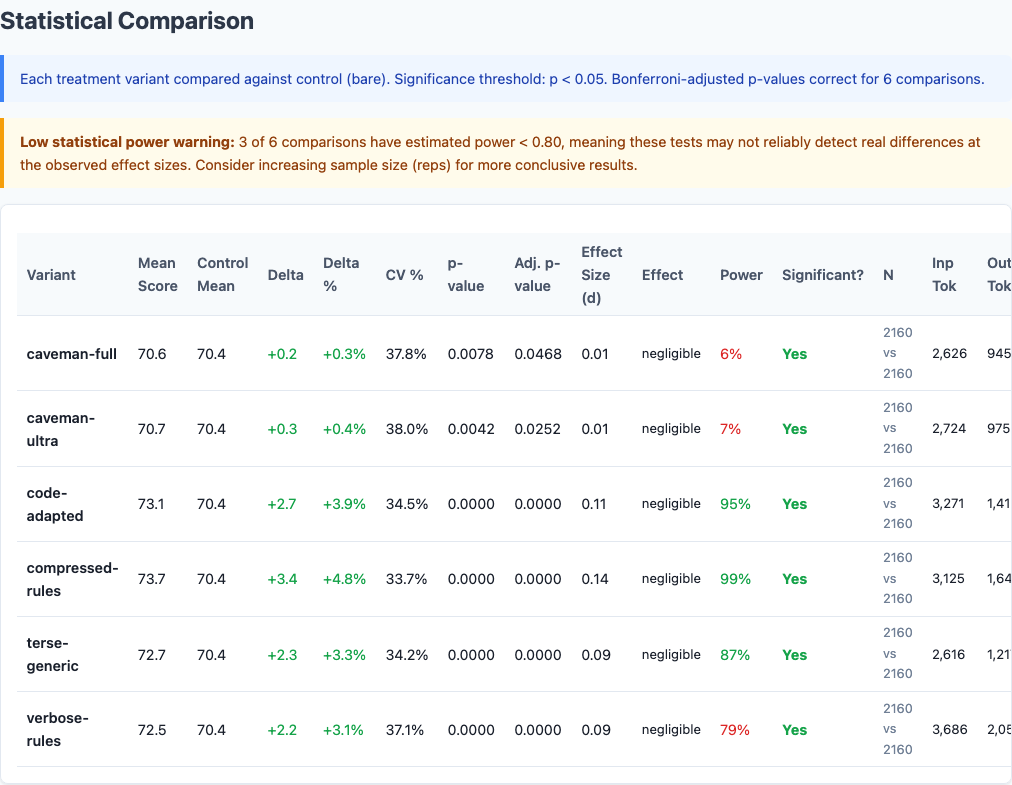
Statistical significance analysis.
Limitations
- Token counts are approximate. We estimated token counts using whitespace heuristics rather than exact tokenization. The ~80 token sweet spot could be off by 10-20 tokens in either direction.
- Claude models only. Other model families (GPT-4, Gemini, etc.) may have different compression preferences. But the pattern across Haiku, Sonnet, and Opus suggests this is a general property of transformer-based LLMs.
- Single-file tasks. These are isolated coding tasks. CLAUDE.md instructions for multi-file projects, architectural standards, or deployment procedures may have different optimal compression levels.
- No interaction with other strategies tested. We didn’t test compression combined with chain-of-thought, personas, or targeted constraints. Interaction effects could exist.
- Compression strategies could be varied further. We tested seven variants, but there’s a large space of possible compression approaches. Structured bullets, numbered lists, markdown formatting, and other organizational strategies could perform differently.
Try It Yourself
The output compression experiment configuration and all data are open source:
pip install claude-benchmark
# Run the output compression experiment
claude-benchmark experiment run experiments/output-compression.toml
# Generate the report
claude-benchmark report
# See the results
open results/*/report.htmlYou can also define your own compression variants in the experiment TOML and test them against your specific codebase conventions. If you find a compression strategy that beats compressed-rules, I’d like to see the data.
Full experiment configuration: experiments/output-compression.toml
For the complete picture of what works in CLAUDE.md optimization, see the init vs best-practices experiment and the targeted constraints experiment. For the synthesis of all benchmark results, see the capstone-v2 experiment.