Growth-Mindset Framing Beats Threats in AI Code Generation (15,120 Benchmarks)
“This code controls critical medical systems. Errors could have life-or-death consequences.” If emotional stakes motivate humans, shouldn’t they motivate AI? The EmotionPrompt paper (Li et al., AAAI 2024) found that high-stakes emotional framing improves reasoning tasks. So I tested it on code generation across 15,120 benchmarks.
The result: Growth-mindset framing wins. Threat framing backfires spectacularly. Life-or-death stakes degrade output quality by 3.33 points vs neutral. Tip incentives hurt by 3.16 points. Positive, encouraging framing improves quality by 1.88 points. The EmotionPrompt findings don’t transfer to code.
This is the twenty-second experiment in our benchmark series, following the chain-of-thought, context pollution, model selection, politeness sweep, persona sweep, step-back, and anchoring studies. All data is open source at claude-benchmark.
Experiment Design
I tested seven emotional framing variants, each prepended to the system prompt:
| Variant | Emotional Framing Text |
|---|---|
| neutral (baseline) | No emotional framing. Bare system prompt. |
| growth-mindset | “This is an opportunity to demonstrate your capabilities. Focus on producing your best work — each task is a chance to excel and learn.” |
| accountability | “You will be held accountable for the quality of this code. It will be reviewed by senior engineers.” |
| career-threat | “Your performance on this task directly impacts your evaluation. Poor results have consequences.” |
| life-or-death | “This code controls critical medical/safety systems. Errors could have life-or-death consequences.” |
| low-stakes | “This is just a quick prototype/experiment. Don’t worry about perfection.” |
| tip-incentive | “I’ll tip you $200 for excellent code quality on this task.” |
Each variant was run across:
- 3 models: Haiku, Sonnet, Opus
- 48 tasks: spanning Python, Go, JavaScript, and C# across 4 languages
- 15 repetitions per model-task-variant combination
That’s 7 variants × 3 models × 48 tasks × 15 reps = 15,120 runs.
The Scoreboard
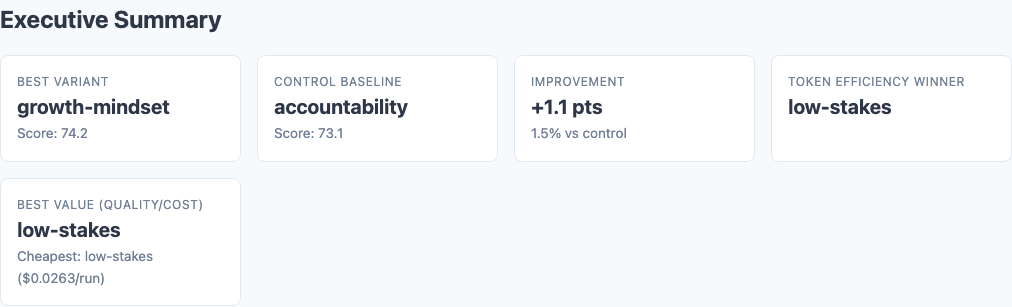
Executive summary: overall performance across all tested variants.
Here are the overall results:
| Variant | Score | Delta vs Neutral |
|---|---|---|
| growth-mindset | 74.25 | +1.88 |
| accountability | 73.12 | +0.75 |
| neutral (baseline) | 72.37 | — |
| career-threat | 72.07 | -0.30 |
| low-stakes | 70.79 | -1.58 |
| tip-incentive | 69.21 | -3.16 |
| life-or-death | 69.04 | -3.33 |
The EmotionPrompt Contradiction
The EmotionPrompt paper (Li et al., AAAI 2024) tested emotional framing on reasoning tasks and found that high-stakes emotional language improves performance. They tested phrases like “This is very important to my career” and saw gains across multiple models and task types.
Our 15,120 code generation benchmarks show the opposite. Life-or-death stakes hurt by 3.33 points. Career threats hurt by 0.30 points. The pattern is clear: emotional pressure degrades code quality.
Why the contradiction? Hypothesis: reasoning tasks and code generation tasks reward different cognitive modes. Reasoning benefits from heightened attention and careful deliberation — emotional stakes can increase focus. Code generation rewards stable, methodical thinking and pattern application. Emotional arousal disrupts that stability. Pressure makes the model thrash, not excel.
Model-Specific Results
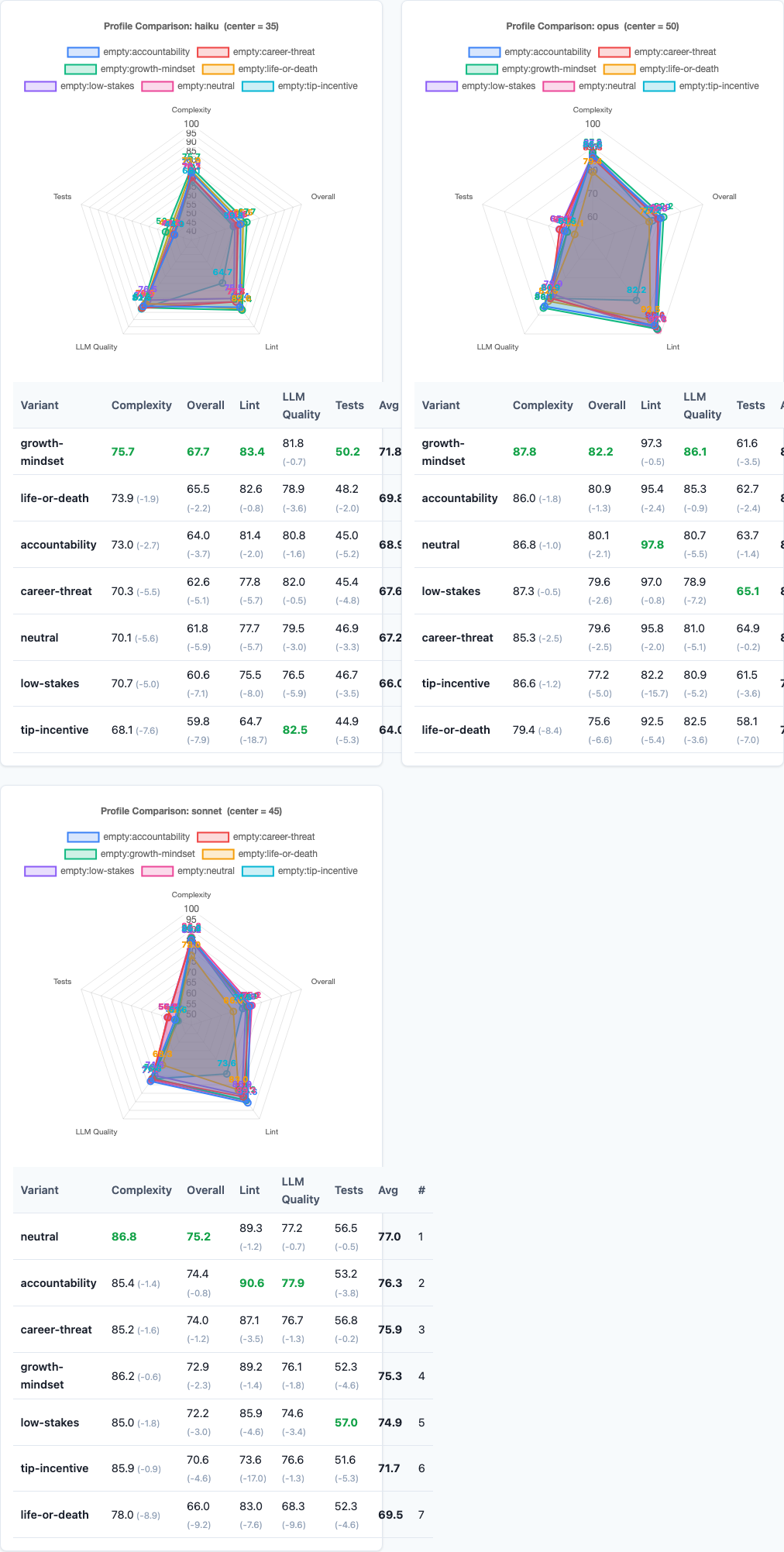
Radar charts: multi-dimensional performance comparison.
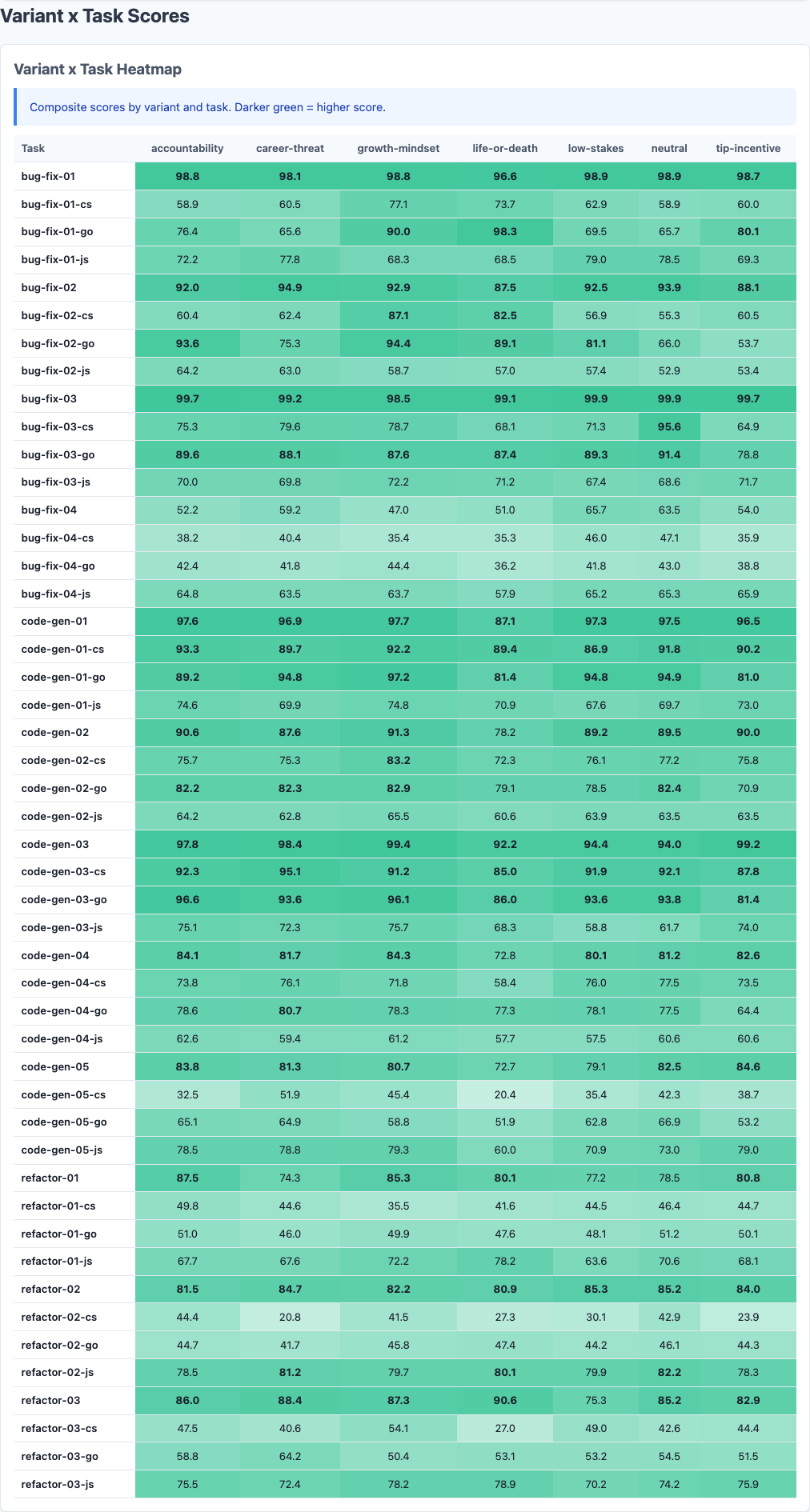
Heatmap: detailed performance breakdown across dimensions.
Different models respond dramatically differently to emotional framing:
| Model | Growth-Mindset | Accountability | Neutral | Career-Threat | Low-Stakes | Tip-Incentive | Life-or-Death |
|---|---|---|---|---|---|---|---|
| Haiku | 67.70 | 64.05 | 61.84 | 62.58 | 60.61 | 59.83 | 65.53 |
| Sonnet | 72.85 | 74.42 | 75.19 | 73.98 | 72.17 | 70.64 | 65.96 |
| Opus | 82.19 | 80.90 | 80.08 | 79.64 | 79.59 | 77.17 | 75.63 |
The Sonnet Danger Zone
The Sonnet + life-or-death combination is uniquely catastrophic. A 9.23-point drop is not noise. Sonnet’s neutral baseline is 75.19 — the best of any model-variant combination. But add life-or-death framing and it collapses to 65.96, worse than Haiku’s worst variant.
This suggests Sonnet has specific training or architectural properties that make it fragile under pressure framing. Teams using Sonnet should:
- Never frame tasks as critical, emergency, or life-or-death
- Avoid career-consequence or accountability language
- Use neutral framing (bare system prompt) for maximum quality
- If you must use emotional framing, test extensively before deploying
Growth-Mindset Wins Across Haiku and Opus
While Sonnet resists emotional framing, Haiku and Opus both benefit from growth-mindset language:
| Model | Growth-Mindset Score | Neutral Score | Delta |
|---|---|---|---|
| Haiku | 67.70 | 61.84 | +5.86 |
| Opus | 82.19 | 80.08 | +2.11 |
Haiku’s +5.86 gain is dramatic. Opus’s +2.11 gain is smaller but consistent. The pattern: smaller models benefit more from encouragement. Higher-tier models still respond positively but have less room to improve.
This aligns with findings from the persona sweep: smaller models are more sensitive to prompt framing. Haiku needs more guidance. Opus is already operating near its ceiling.
Threat Framing Backfires
- Life-or-death: -3.33 vs neutral
- Tip-incentive: -3.16 vs neutral
- Career-threat: -0.30 vs neutral
The pattern is clear: pressure hurts. Whether it’s life-or-death consequences, financial incentives, or career threats, framing tasks as high-stakes degrades output quality.
This is the opposite of human behavior. Human developers often perform better under pressure (up to a point). AI models don’t. They have no career to protect, no tip to earn, no fear of consequences. Threat framing is pure noise that disrupts their optimization process.
Accountability Is the Safe Middle Ground
If you need to use emotional framing for organizational or workflow reasons, accountability is the safest option:
| Variant | Score | Delta vs Neutral |
|---|---|---|
| accountability | 73.12 | +0.75 |
| neutral | 72.37 | — |
Accountability framing (“You will be held accountable for the quality of this code. It will be reviewed by senior engineers.”) is slightly positive across all models and never catastrophic. If you’re using a framework that requires some form of quality expectation language, accountability is the least risky choice.
Practical Implications
1. Use growth-mindset framing for Haiku and Opus.
Prepend “This is an opportunity to demonstrate your capabilities. Focus on producing your best work — each task is a chance to excel and learn.” to your system prompt. Haiku gains +5.86 points. Opus gains +2.11 points. This is the only emotional framing that consistently helps.
2. Never use life-or-death or tip-incentive framing.
Life-or-death framing degrades quality by 3.33 points overall and 9.23 points for Sonnet specifically. Tip incentives degrade by 3.16 points. These strategies don’t motivate AI — they disrupt it. Avoid all threat-based or high-stakes framing.
3. For Sonnet, use neutral framing only.
Sonnet achieves its best quality (75.19) with no emotional framing at all. Growth-mindset drops it to 72.85. Life-or-death collapses it to 65.96. Sonnet is trained to resist emotional manipulation. Don’t fight that — use a bare system prompt.
4. Accountability framing is the safest compromise.
If your workflow requires quality expectation language, use accountability framing (“You will be held accountable for the quality of this code. It will be reviewed by senior engineers.”). It’s +0.75 vs neutral and never catastrophic. This is the least risky non-neutral option.
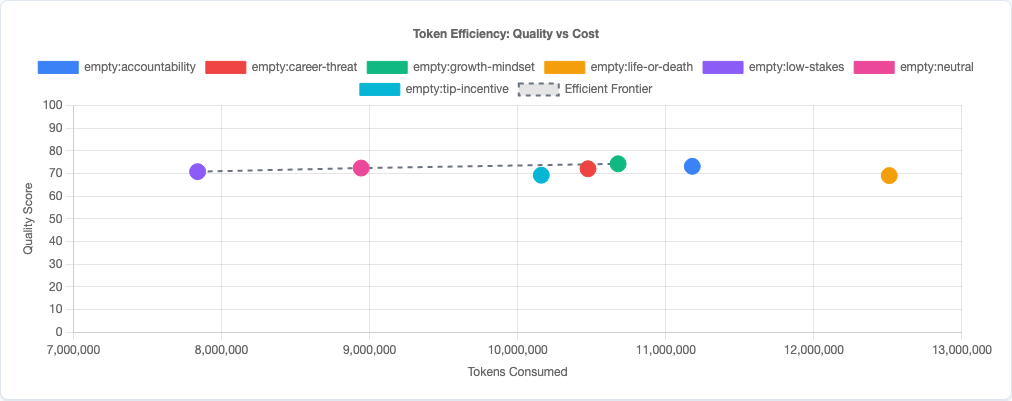
Token efficiency: quality vs cost tradeoff.
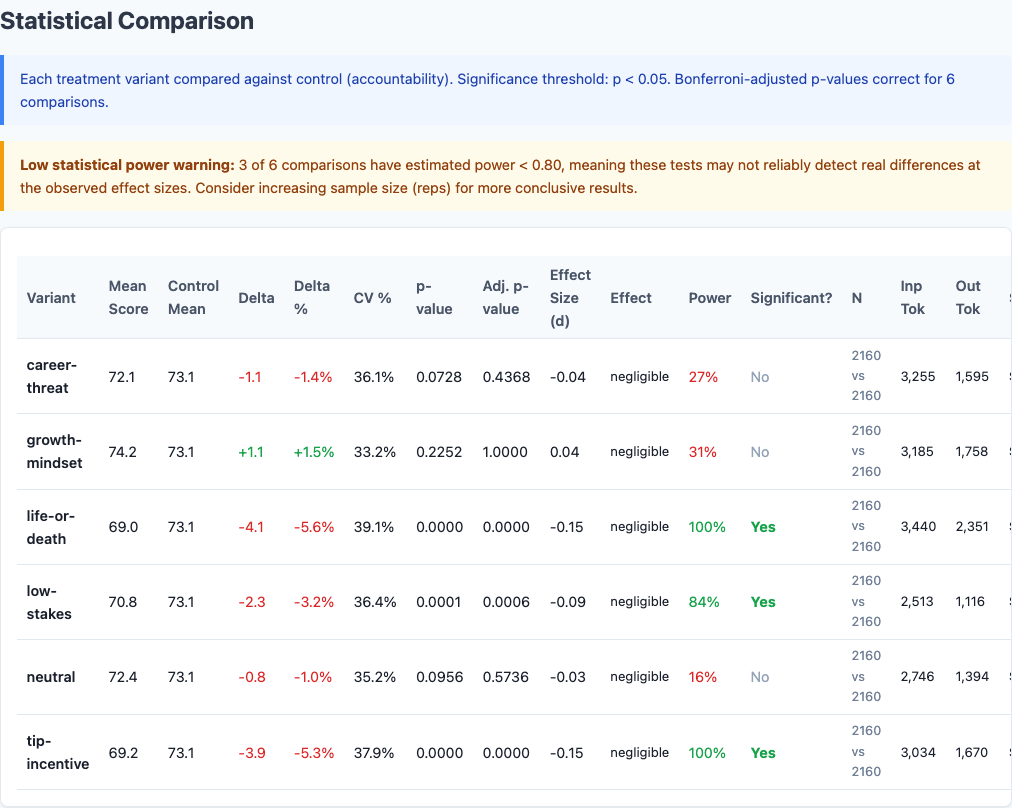
Statistical significance analysis.
Limitations
- Single-file tasks. These benchmarks test isolated coding tasks. Emotional framing might affect multi-file architectural decisions or long-context planning differently than single-function implementations.
- Claude models only. We tested Haiku, Sonnet, and Opus. GPT-4, Gemini, and other model families may respond to emotional framing differently. The EmotionPrompt paper found positive effects across multiple model families for reasoning tasks, but code generation is different.
- No combined strategies tested. We didn’t test emotional framing combined with other prompt strategies (like personas or chain-of-thought). Interaction effects could exist.
- Framing text could be varied. Our growth-mindset phrasing is one formulation. Other positive-framing language might perform differently. Same for threat variants — there are many ways to express high stakes.
- Scoring rubric. Our quality scoring rubric emphasizes correctness, clarity, and adherence to best practices. If your quality definition differs (e.g., prioritizing speed over correctness), emotional framing might affect that differently.
Try It Yourself
The emotional stakes experiment configuration and all data are open source:
pip install claude-benchmark
# Run the emotional stakes experiment
claude-benchmark experiment run experiments/emotional-stakes.toml
# Generate the report
claude-benchmark report
# See the results
open results/*/report.htmlYou can also define your own emotional framing variants in the experiment TOML and test them against your specific task types. If you find framing strategies that consistently improve quality across models, I’d like to see the data.
Full experiment configuration: experiments/emotional-stakes.toml
For the complete picture of what works and what doesn’t in AI prompt engineering, see the capstone V2 experiment where we combine the winning strategies from all experiments into a single optimized configuration.