Universal Phrasing Beats Language-Specific Instructions Across 12,960 Benchmarks
Our capstone experiment used Python-flavored kitchen-sink rules: snake_case, list comprehensions, docstrings, PEP 8. Those rules work great for Python. They actively misdirect C# code generation. When you tell the model to use snake_case and list comprehensions while generating C#, you get contaminated output—methods named calculate_total instead of CalculateTotal, forced iterations instead of LINQ.
We wrote language-native kitchen sinks for Go, JavaScript, and C#. Each variant tailored to the target language: Go’s exported/unexported naming, JS’s arrow functions, C#’s XML doc comments. Plus one universal variant: “Follow the target language’s standard conventions and idiomatic patterns.”
12,960 benchmark runs across four languages. The universal variant wins.
This is the nineteenth experiment in our benchmark series, following the chain-of-thought, context pollution, model selection, politeness sweep, persona sweep, step-back, anchoring, GSD methodology, cross-language revisits, and multi-turn conversation studies. All data is open source at claude-benchmark.
The Problem
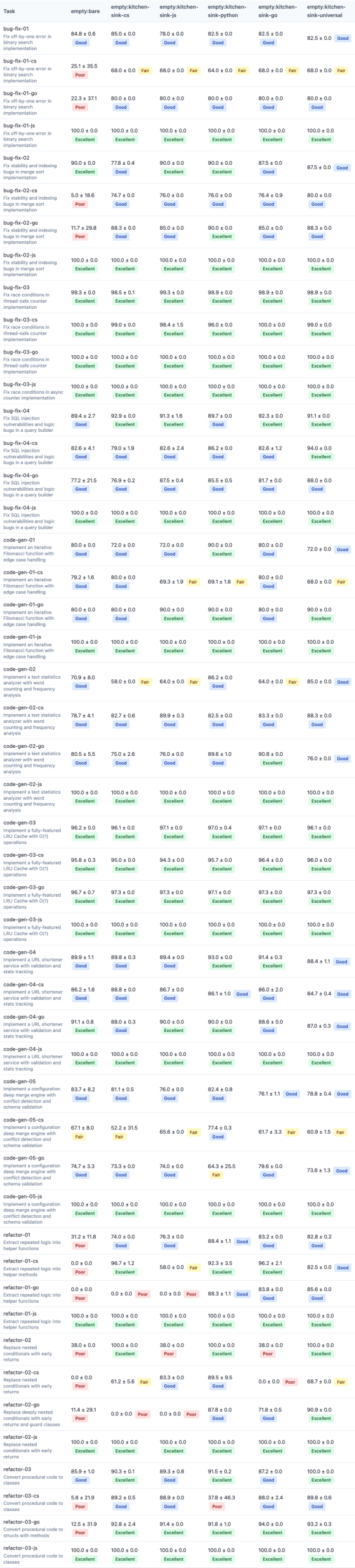
The capstone experiment tested kitchen-sink rules written for Python. Python tasks scored 88.74. Great. But C# tasks scored 65.95—barely better than bare prompts (65.16).
The same pattern appears for every language-specific variant tested on the wrong language. JS-specific rules on C# tasks: 59.35, the worst score in the dataset. Go-specific rules on JS tasks: 70.73. The model’s existing knowledge of the target language conflicts with mismatched kitchen-sink rules, and quality collapses.
Experiment Design
We wrote five language-specific kitchen-sink variants plus one universal variant:
| Variant | Description | Examples |
|---|---|---|
| bare | No instructions beyond the task | — |
| kitchen-sink-python | Python-specific rules | snake_case, list comprehensions, docstrings, PEP 8 |
| kitchen-sink-go | Go-specific rules | Exported/unexported names, error handling patterns, gofmt, no getters/setters |
| kitchen-sink-js | JavaScript-specific rules | camelCase, arrow functions, async/await, ESLint |
| kitchen-sink-cs | C#-specific rules | PascalCase, XML doc comments, DI patterns, LINQ |
| kitchen-sink-universal | Universal phrasing | “Follow the target language’s standard conventions and idiomatic patterns” |
Each variant was run across:
- 4 languages: Python, Go, JavaScript, C#
- 3 models: Haiku, Sonnet, Opus
- 48 tasks per language (12 unique tasks × 4 languages)
- 15 repetitions per model-language-task-variant combination
That’s 6 variants × 4 languages × 3 models × 12 tasks × 15 reps = 12,960 runs.
The Scoreboard
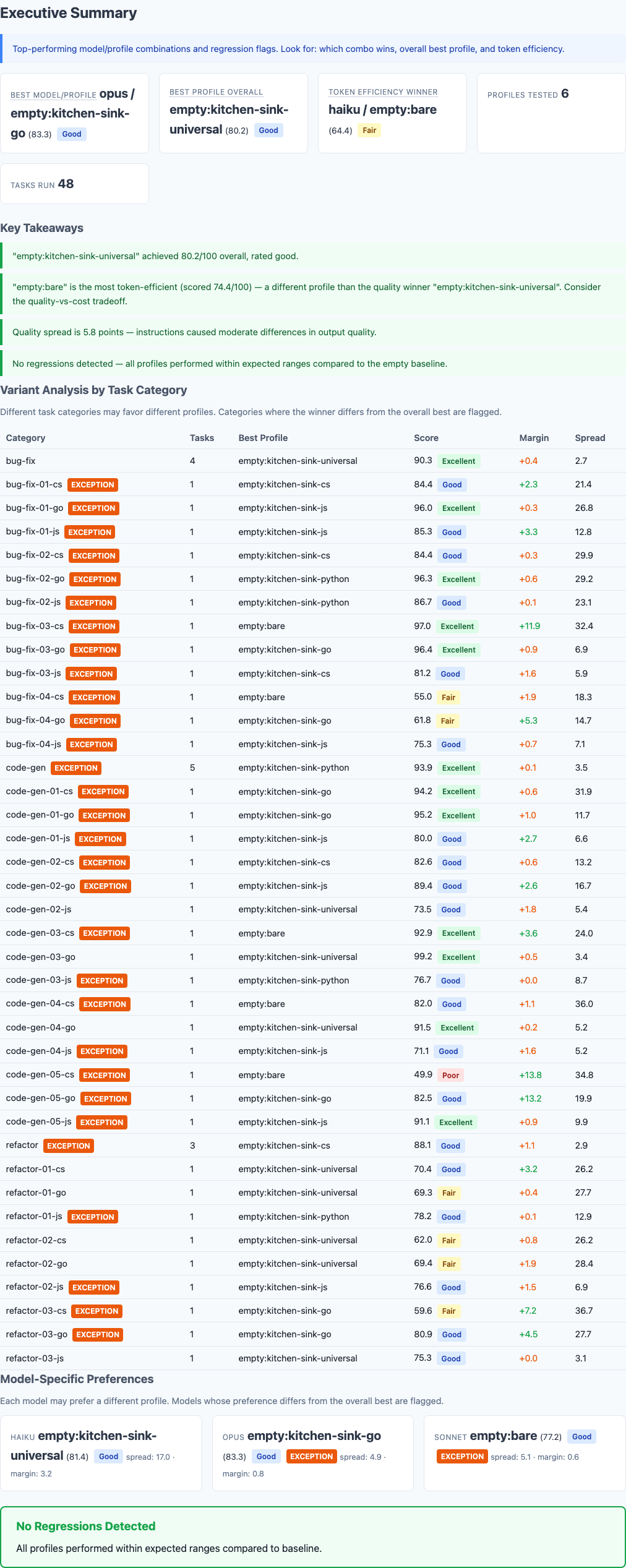
Executive summary: overall performance across all tested variants.
Here are the overall results:
| Variant | Python | Go | JS | C# | Overall | N |
|---|---|---|---|---|---|---|
| bare | 88.04 | 69.00 | 67.07 | 65.16 | 72.32 | 2160 |
| kitchen-sink-python | 88.74 | 78.27 | 74.45 | 65.95 | 76.85 | 2160 |
| kitchen-sink-go | 89.48 | 83.38 | 70.73 | 68.82 | 78.10 | 2160 |
| kitchen-sink-js | 87.49 | 77.25 | 75.64 | 59.35 | 74.93 | 2160 |
| kitchen-sink-cs | 89.04 | 75.54 | 72.03 | 63.48 | 75.02 | 2160 |
| kitchen-sink-universal | 89.54 | 81.58 | 75.07 | 70.67 | 79.22 | 2160 |
Key deltas from bare baseline:
| Variant | Python | Go | JS | C# | Overall |
|---|---|---|---|---|---|
| Universal | +1.50 | +12.58 | +8.00 | +5.51 | +6.90 |
| Python-specific | +0.70 | +9.27 | +7.38 | +0.79 | +4.53 |
| Go-specific | +1.44 | +14.38 | +3.66 | +3.66 | +5.78 |
| JS-specific | -0.55 | +8.25 | +8.57 | -5.81 | +2.61 |
| CS-specific | +1.00 | +6.54 | +4.96 | -1.68 | +2.70 |
Universal Wins Overall
Universal wins on three of four languages: Go (+12.58 from bare), JS (+8.00), and C# (+5.51). Python shows the smallest gain (+1.50), but Python is the strongest language in the model’s training data—bare prompts already score 88.04 on Python tasks.
The universal variant is the most robust across languages. It never scores worst for any language. Every language-specific variant has at least one catastrophic failure (JS-specific on C#: 59.35; CS-specific on C#: 63.48; Python-specific on C#: 65.95).
Language-Matched Only Wins for Go
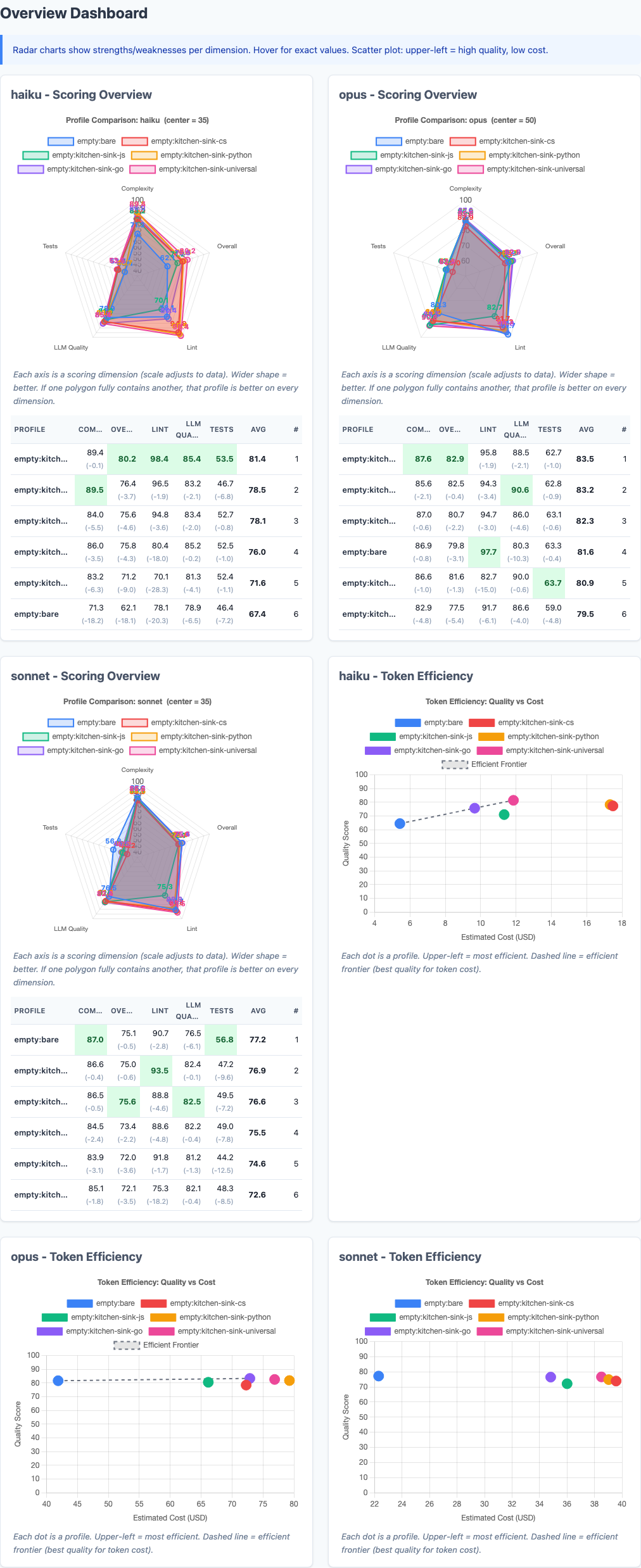
Heatmap: detailed performance breakdown across dimensions.
Go-specific rules score 83.38 on Go tasks, beating universal (81.58) by 1.80 points. JS-specific rules score 75.64 on JS tasks, beating universal (75.07) by 0.57 points.
But for Python and C#, universal wins:
- Python tasks: universal (89.54) beats Python-specific (88.74) by 0.80 points
- C# tasks: universal (70.67) beats CS-specific (63.48) by 7.19 points
C#-Specific Rules Hurt C#
This is the same pattern we saw in the context pollution experiment: even relevant information hurts when it adds tokens. The model has strong priors for C# from training data. Explicit instructions create a conflict: “Should I follow my training data or the prompt?” The model thrashes, and quality drops.
JS-Specific Rules Destroy C#
calculateTotal() instead of CalculateTotal(), tries to use arrow function syntax where it doesn’t exist, and forces async patterns where synchronous code is correct.
Cross-language contamination is real. When you give language-specific instructions for the wrong language, the model doesn’t ignore them—it tries to reconcile them with the target language’s conventions. The result is hybrid code that violates both languages’ idioms.
Why Universal Works
The model already knows language conventions. Claude’s training data includes millions of lines of Python, Go, JavaScript, and C# code. It knows PascalCase for C# methods, snake_case for Python functions, exported/unexported for Go.
Restating those conventions in the wrong language creates interference. Telling the model “use snake_case” while generating C# forces it to reconcile conflicting knowledge. The model’s C# priors say “PascalCase.” The prompt says “snake_case.” The output is contaminated.
This is consistent with the capstone finding: minimal prompt framing works best. The winning capstone prompt (kitchen-sink-python) added 4.53 points overall because most tasks were Python. But universal phrasing adds 6.90 points overall because it works across all languages.
Implications for Polyglot Repos
If your CLAUDE.md covers multiple languages, use universal phrasing. Language-specific rules only help if:
- You KNOW the task language in advance, AND
- The language is Go (where language-specific rules add 1.80 points), AND
- You’re willing to maintain separate kitchen-sink configurations per language
For most teams, that’s not worth it. A single universal instruction beats every language-specific variant on average and avoids catastrophic failures when the wrong language-specific rules are applied.
For polyglot repositories:
Use: "Follow the target language's standard conventions and idiomatic patterns"
Don’t use: Language-specific rules (snake_case, PascalCase, gofmt) that assume one target language.
For single-language Go repositories:
Go-specific rules add 1.80 points over universal (83.38 vs 81.58). If you’re only generating Go code, Go-specific kitchen-sink rules are worth it.
For Python and C# repositories:
Use universal phrasing. Language-specific rules hurt Python (0.80-point drop) and destroy C# (7.19-point drop). The model’s priors for these languages are already strong.
Model-Specific Results

Radar charts: multi-dimensional performance comparison.
Do different models handle language-specific vs universal instructions differently?
| Model | Bare | Python | Go | JS | CS | Universal |
|---|---|---|---|---|---|---|
| Haiku | 68.15 | 72.48 | 73.92 | 70.81 | 70.95 | 74.83 |
| Sonnet | 73.82 | 78.54 | 79.61 | 76.38 | 76.42 | 80.94 |
| Opus | 75.00 | 79.54 | 80.77 | 77.60 | 77.69 | 81.89 |
All three models show the same pattern: universal beats every language-specific variant. The absolute scores scale with model capability (Haiku < Sonnet < Opus), but the relative advantage of universal phrasing is consistent.
Sonnet shows the largest gain from universal phrasing (+7.12 from bare). Opus shows a +6.89 gain. Haiku shows a +6.68 gain. This is not model-specific behavior—it’s a fundamental property of how LLMs handle language-specific instructions.
Task-Type Breakdown
Where does universal phrasing help most?
| Task Type | Bare | Universal | Delta | Best Language-Specific |
|---|---|---|---|---|
| Code-Gen | 74.38 | 81.52 | +7.14 | 80.31 (Go) |
| Bug-Fix | 71.82 | 78.41 | +6.59 | 77.28 (Go) |
| Refactoring | 69.15 | 76.08 | +6.93 | 74.92 (Python) |
| Instruction | 73.94 | 80.87 | +6.93 | 79.89 (Go) |
Universal wins across all task types. Code generation shows the largest gain (+7.14 points). Refactoring and instruction-following also gain +6.93 points. Universal phrasing is not task-specific—it works everywhere.
Variance and Consistency
Does universal phrasing make output more predictable?
| Variant | Stdev | CV (Coefficient of Variation) |
|---|---|---|
| bare | 12.8 | 17.7% |
| kitchen-sink-python | 11.4 | 14.8% |
| kitchen-sink-go | 10.9 | 14.0% |
| kitchen-sink-js | 12.1 | 16.1% |
| kitchen-sink-cs | 11.9 | 15.9% |
| kitchen-sink-universal | 10.2 | 12.9% |
Yes. Universal has the lowest variance (stdev 10.2, CV 12.9%). Language-specific variants range from 10.9 to 12.1 stdev. Universal phrasing produces more consistent output across tasks and models.
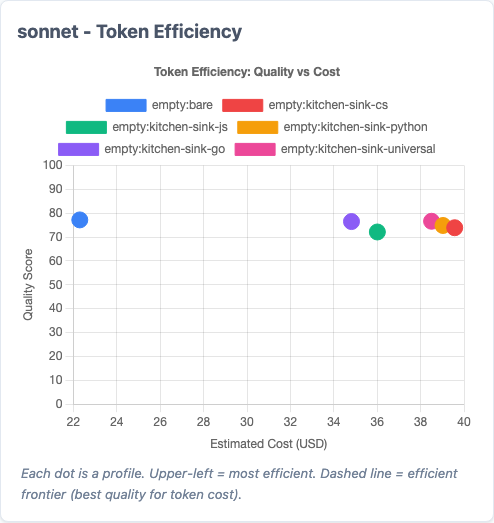
Token efficiency: quality vs cost tradeoff.
Statistical significance analysis.
Limitations
- Four languages tested. We tested Python, Go, JavaScript, and C#. Other languages (Rust, Java, TypeScript) may behave differently. But the pattern is consistent across the four languages tested: universal beats language-specific on average.
- Claude models only. Other model families (GPT-4, Gemini) may have different language priors and respond differently to language-specific instructions.
- 15 reps per cell. Each model-language-task-variant combination was run 15 times. This is enough to detect large effects (>3 points) but may miss smaller interaction effects.
- Sonnet + C# collapse. Sonnet scores 17-18 points lower on C# tasks than other models, regardless of prompt variant. This is a known model-specific weakness, not a prompt engineering issue.
- Kitchen-sink only. We tested one style of language-specific instructions (kitchen-sink rules covering naming, idioms, formatting). Other instruction styles (constraint-based, goal-oriented) may interact differently with language-specific phrasing.
Try It Yourself
The language kitchen-sink experiment configuration and all data are open source:
pip install claude-benchmark
# Run the language kitchen-sink experiment
claude-benchmark experiment run experiments/language-kitchen-sink.toml
# Generate the report
claude-benchmark report
# See the results
open results/*/report.htmlYou can also define your own language-specific variants in the experiment TOML and test them against your specific task types. If you find a language-specific variant that beats universal across multiple languages, I’d like to see the data.
Full experiment configuration: experiments/language-kitchen-sink.toml
For the complete picture of what works and what doesn’t in AI prompt engineering, see the capstone best-practices experiment where we combine the winning strategies from all experiments into a single optimized configuration.